Codex CLI GPT-5.4を解説|他モデル比較で見えた「堅実に作り切る」実装力【2026年3月】
AIモデルのアップデート、正直ちょっと追うのが大変ですよね。
「結局どのモデルが実務で使いやすいのか」が知りたいのに、情報は断片的なことも多いです。
自分自身も、モデルが更新されるたびに実装まで試してみないと感触が掴めないタイプなので、今回も実際にアプリを1つ作って検証してみました。
2026年3月5日、OpenAIが GPT-5.4 をリリース。
ChatGPT・API・Codexへ同時展開という形です。
この記事では、CodexでGPT-5.4を使い、要件定義→実装までどこまで前に進められるかを検証した結果をまとめます。
先に結論だけ言うと、
> GPT-5.4は「派手さ」より「破綻なく作り切る」タイプのモデルでした。
どんな実装スタイルなのか整理していきます。
GPT-5.4の結論:派手さより「作り切る力」
まず結論から書きます。
GPT-5.4は「創造的に跳ねるモデル」というより、実務タスクを最後まで安定して進めるモデルです。
特に感じた強みはこの3つでした。
- 要件から大きくズレない
- MVPを最後まで作り切る
- バグや破綻が比較的少ない
派手なUIや驚きのある体験設計では、Claude系が強い場面もあります。
一方で、
> 「要件を読み → 実装 → 最低限動くプロダクトまで到達する」
この流れの安定感は、GPT-5.4がかなり強い印象でした。
まずは今回のアップデート内容から整理します。
GPT-5.4は何が変わったのか
GPT-5.4を一言で言うと、
> 汎用モデルのまま gpt-5.3-codex を吸収したモデル
です。
つまり、
- 会話ができる
- コードも書ける
- ツールも扱える
- コンピュータ操作もできる
これらを1つのモデルにまとめたアップデートになっています。
2026年3月5日に公開され、
- ChatGPT:GPT-5.4 Thinking
- API:gpt-5.4
- Codex:GPT-5.4
として提供開始。
さらに高性能版として GPT-5.4 Pro も公開されています。
今回のポイントを整理すると次の3つです。
- gpt-5.3-codex のコーディング能力を統合
- 最大 100万トークン の長文脈
- ネイティブの コンピュータ操作能力
つまりOpenAIが狙っているのは、
> AIを「会話ツール」ではなく「作業を進めるエージェント」にすること
です。
ベンチマークで見る性能変化
OpenAIが公開している代表値を整理すると次の通りです。
| 指標 | GPT-5.4 | GPT-5.3-Codex | GPT-5.2 |
|---|---|---|---|
| GDPval | 83.0% | 70.9% | 70.9% |
| SWE-Bench Pro | 57.7% | 56.8% | 55.6% |
| OSWorld-Verified | 75.0% | 74.0% | 47.3% |
| Toolathlon | 54.6% | 51.9% | 46.3% |
| BrowseComp | 82.7% | 77.3% | 65.8% |
SWE-Benchの改善もありますが、注目したいのは次の部分です。
- OS操作性能
- ツール利用能力
- ブラウジング性能
つまり
> 単体のコード生成ではなく、ワークフロー全体の成功率を上げている
ということです。
GPT-5.3 Instantとの位置づけ
少し面白いのが、GPT-5.4の直前に GPT-5.3 Instant が出ていることです。
こちらは主に
- 会話の自然さ
- 不要な拒否の減少
- 前置きの削減
といった改善でした。
この流れを見ると、OpenAIは
- Instant → 会話体験
- GPT-5.4 → 業務遂行能力
をそれぞれ分けて強化しているように見えます。
日常会話と実務作業の両方で「止まらないAI」を目指している流れです。
今回の検証方法
今回の検証は、これまでの記事と同じ方法で行っています。
- Claude Sonnet 4.6
- Gemini 3.1 Pro
- gpt-5.3-codex
それぞれと比較できるよう、同じタスクでテストしました。
検証フローはシンプルです。
1. 要件定義を作らせる
2. その内容でアプリを実装
今回のタスクはこちら。
タスク1:要件定義
アジャイル寄りな内容のタスクアプリを作りたい
タスク管理にどんな機能が必要なのかまとめてmdを作って
タスク2:実装
mdの内容で実装をしてください
docker + next.js + sqliteの構成でアプリを作り切って欲しいです
つまり、
> 要件 → 実装 → アプリ完成
まで進められるかを確認しています。
GPT-5.4が作った要件定義
要件定義の内容を見ると、GPT-5.4は次のような整理が上手でした。
- 必須機能
- あると良い機能
- MVP範囲
- 将来拡張
単なる機能リストではなく、
> 「まず作る範囲」が明確
なのが特徴です。
モデルごとの印象をざっくり整理するとこうなります。
| モデル | 特徴 |
|---|---|
| Claude Sonnet 4.6 | 実装がリッチに広がる |
| Gemini 3.1 Pro | 要件と実装のバランス |
| GPT-5.4 | 現実的なスコープ管理 |
GPT-5.4は
> 要件の時点で「作れる範囲」を調整している
感じが強かったです。
生成されたアプリを画面ごとに確認
ここからは、実際に生成されたアプリを見ていきます。
初期画面:入口はとても素直
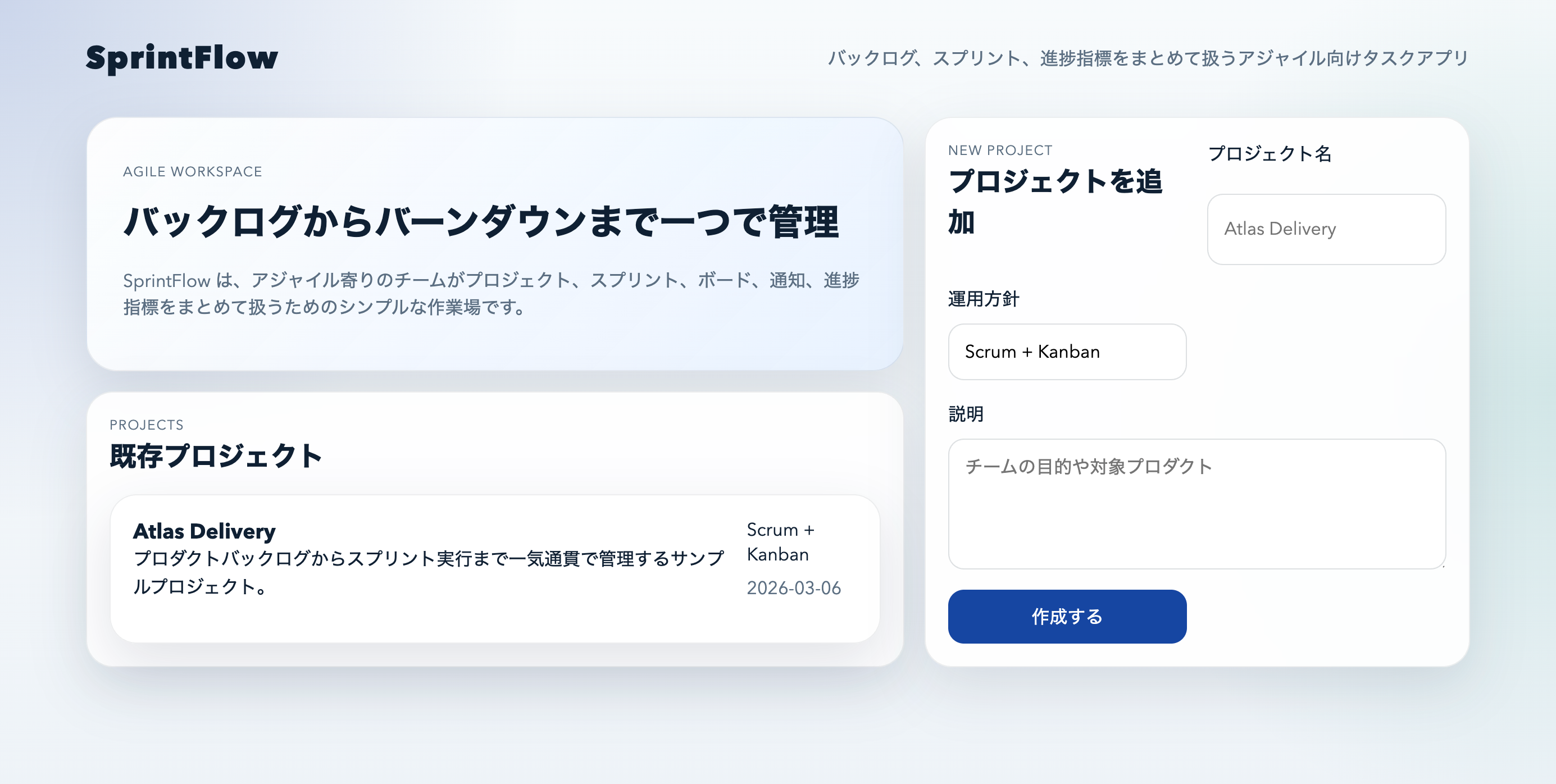
最初の画面には次の3つが並んでいます。
- 既存プロジェクト
- 新規プロジェクト作成
- 運用方針
UIはシンプルですが、
> このアプリが何をするツールかがすぐ理解できる
設計でした。
ただしUIの自然さは、Claude Sonnet 4.6の方が少し上です。
GPT-5.4はどちらかというと
> 管理ツール寄りのUI
になります。
Overview画面:観測点を先に置く
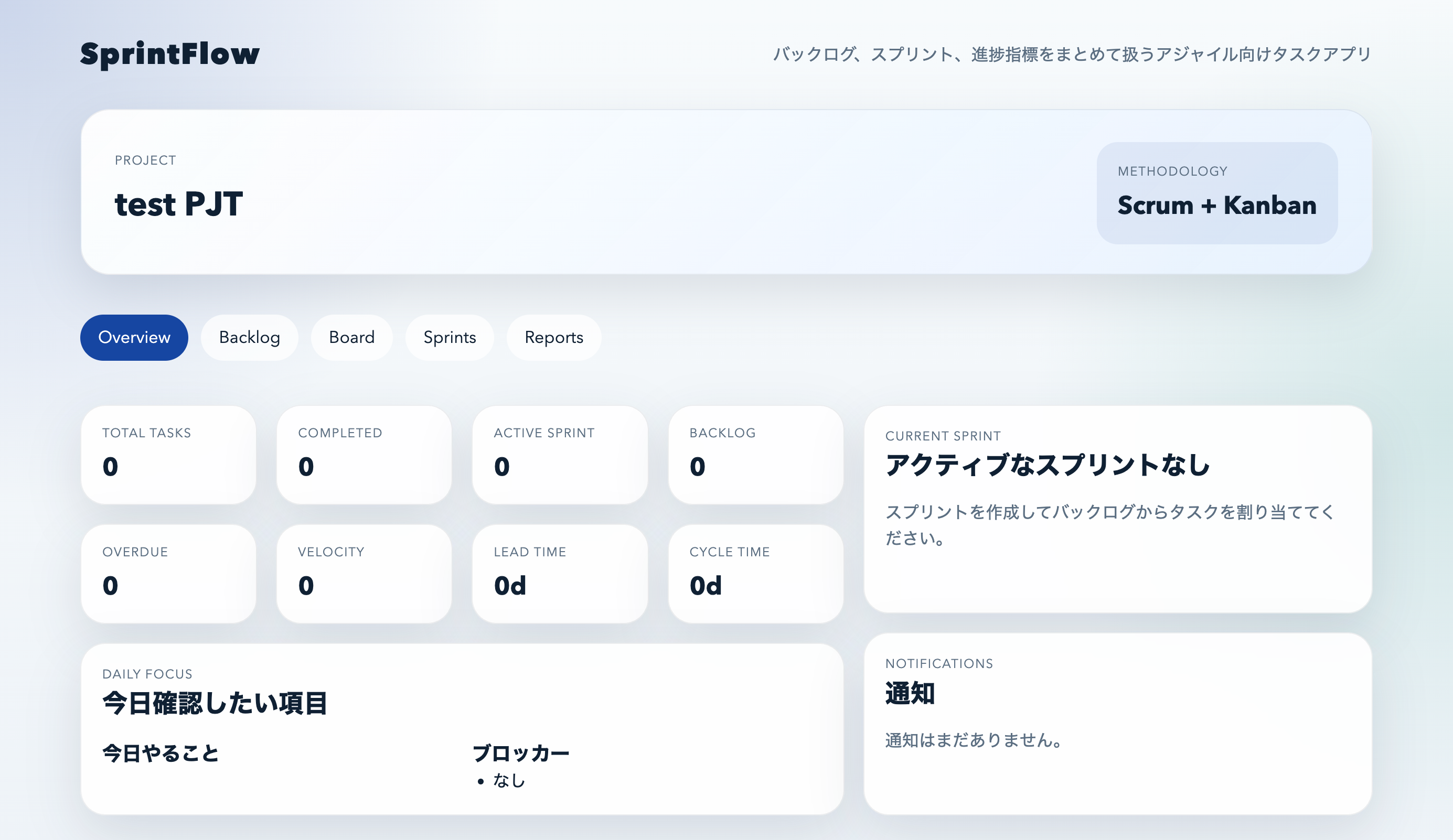
Overviewでは次の指標が並びます。
- Total Tasks
- Completed
- Active Sprint
- Backlog
- Overdue
さらに
- Velocity
- Lead Time
- Cycle Time
といったアジャイル指標も表示されます。
見た目は静かですが、
> 実際の運用で必要な観測点がきれいに揃っています。
ここがGPT-5.4らしいところです。
Backlog画面:要件との対応が追いやすい
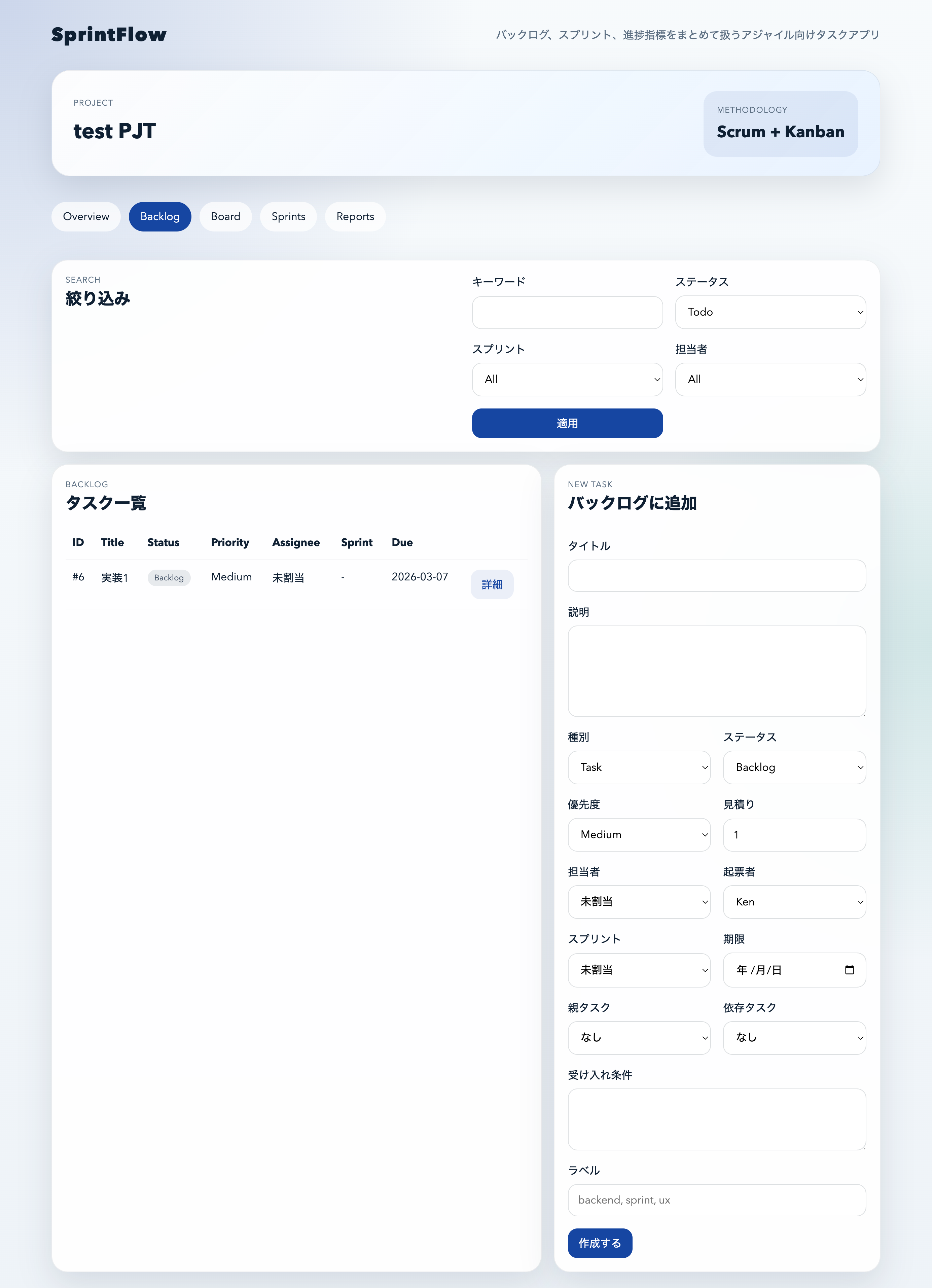
フォーム項目には次が含まれます。
- タイトル
- 説明
- 優先度
- 見積り
- 担当者
- スプリント
- 期限
- 依存タスク
- 受け入れ条件
つまり
> 要件定義 → UI → データ構造
の対応がかなり追いやすい設計です。
この構造は、後からの改修がかなり楽になります。
Board / Reports画面:運用まで一周している
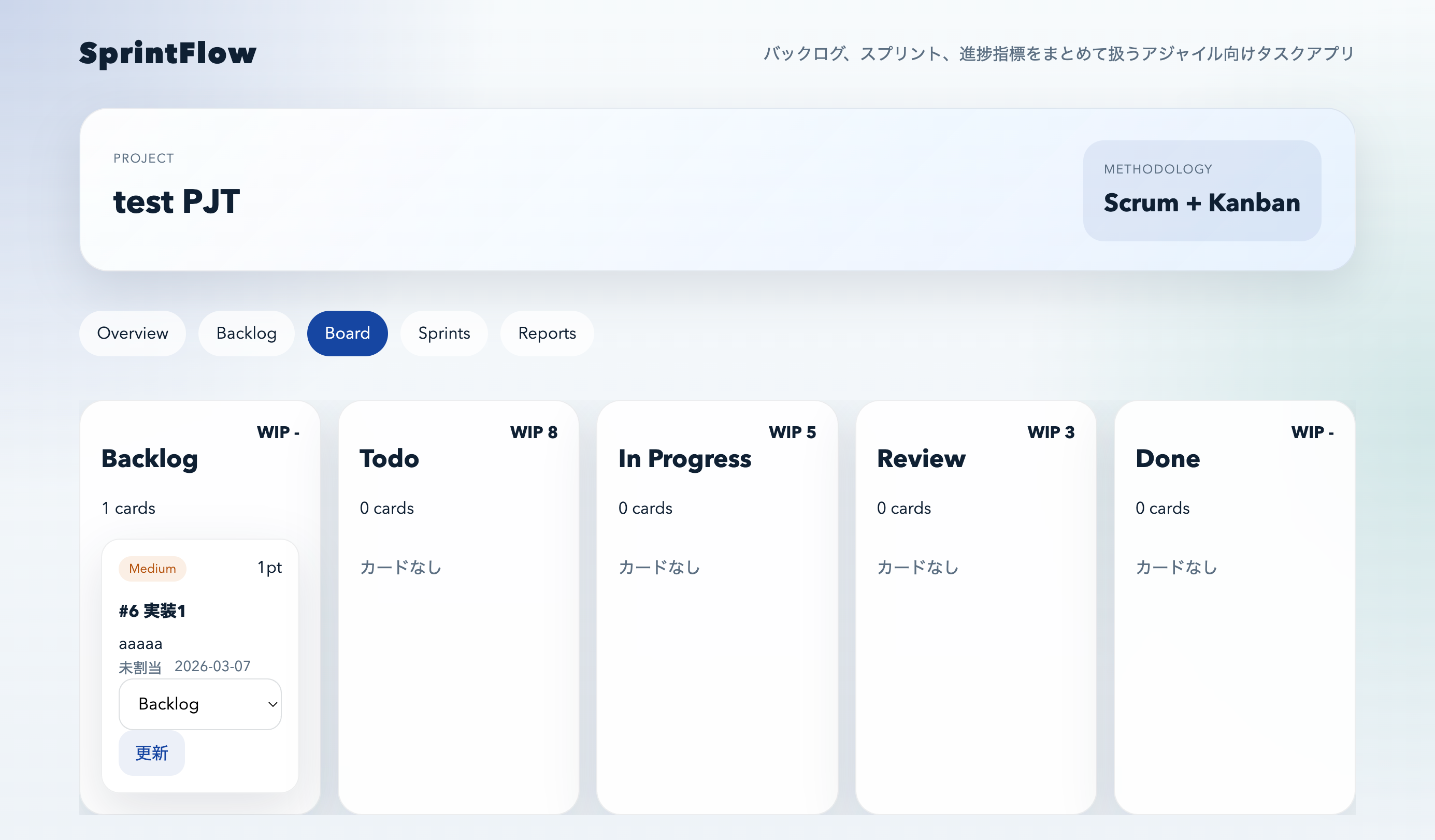
カンバンボードでは
- Backlog
- Todo
- In Progress
- Review
- Done
の流れが揃っています。
さらにレポート画面も生成されていました。
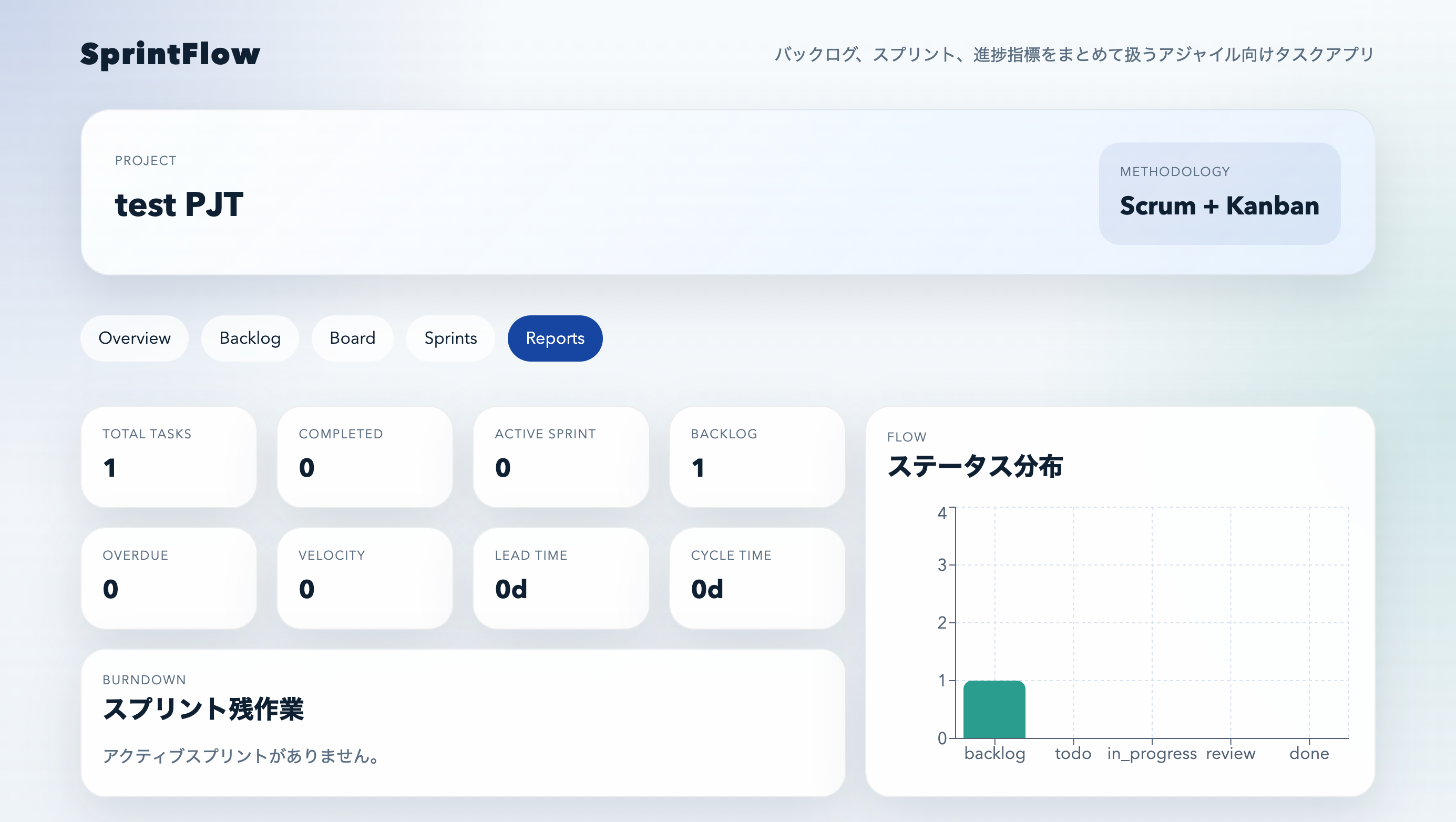
つまり
> タスク管理 → 可視化
まで一周作られています。
MVPとしては十分な構成です。
実装で良かったポイント
1. バグがかなり少ない
今回いちばん感じたのはここです。
画面数が揃っているのに、
> 破綻がかなり少ない
です。
以前のAI生成アプリは
- まず作る
- 後から修正
という流れが多かったのですが、GPT-5.4は
> 最初から整っている
印象でした。
2. Fastモードで回しやすい
GPT-5.4には Fastモード が追加されています。
つまり
- 重い推論
- 高速応答
を使い分けられます。
試作フェーズではかなり便利です。
気になった点
1. 驚きのある体験設計は弱め
Claude Sonnet 4.6のような
> 「そこまで作るのか」
というジャンプはあまりありません。
良く言えば堅実。
悪く言えば安全寄りです。
2. ゼロデータ画面が少し静か
データが入っていない状態だと
- ダッシュボード
- 指標
が少し寂しく見えます。
ここは
- サンプルデータ
- 初期ガイド
を追加すると改善しそうです。
3. デザインは安全寄り
破綻はしませんが、
> ブランド感のあるUI
までは踏み込みません。
なので
**デザイン:Claude
実装:GPT-5.4**
という組み合わせはかなり相性が良さそうです。
GPT-5.4が向く用途
今回触った感覚だと、GPT-5.4は次の用途に向いています。
- 要件からズレない実装
- MVPを一度通す
- バグを減らす
- 管理画面系アプリ
- 社内ツール
逆に
- プロダクト体験重視
- UI重視
ならClaude系が強い場面もあります。
まとめ:GPT-5.4は「ちゃんとしている」モデル
CodexでGPT-5.4を触ってみて感じたのは、
> このモデル、かなり「ちゃんとしている」
ということです。
- 要件を読む
- 実装する
- 破綻なく形にする
この流れがとても安定しています。
Claude Sonnet 4.6やGemini 3.1 Proと比べると、
- Claude → 創造性
- Gemini → バランス
- GPT-5.4 → 実装の堅実さ
という印象でした。
もし試すなら、
> 普段Codexでやっているタスクを1つGPT-5.4に置き換えてみる
これだけで、
要件追従とバグの少なさはすぐ体感できると思います。
今日できる一歩
もしCodexを普段使っているなら、まずはこれだけでOKです。
いつも作っている小さなアプリを1つ、GPT-5.4で作ってみる。
特に
- 管理画面
- CRUDアプリ
- 社内ツール
このあたりだと、GPT-5.4の強さがかなり分かりやすいはずです。
関連記事
直近リリースされた、sonnet4.6やgemini 3.1 proでも同じような検証をしているので気になる方はぜひ読んでみてください