Claude Sonnet 4.6を実機検証してわかった、4.5との「実装力」の決定的な差【2026年2月】
「Claude Sonnet 4.6って、結局4.5と何が違うの?」
「Opusを使い続けるべき? Sonnetに切り替えていい?」
このあたり、気になっている方は多いんじゃないでしょうか。
正直に言うと、自分もリリース前は「いつものマイナーアップデートでしょ」くらいの温度感でした。ところが実際に同じプロンプトで4.5と4.6にアプリを作らせてみたら、出てきたものがまるで別物だったんです。
この記事では、ToDoアプリの実装比較で見えた具体的な差分と、料金・性能・使える環境まで、ひと通りまとめています。「自分の用途なら、どっちを選ぶべきか」の判断材料になるはずです。
そもそもClaude Sonnet 4.6って何? 30秒でわかる概要
Claude Sonnet 4.6は、Anthropicが2026年2月17日にリリースしたAIモデルです。
Claudeには性能の異なる3つのグレードがあります。最高性能のOpus、バランス型のSonnet、軽量・高速のHaiku。多くのユーザーが日常的に使っているのはSonnetで、今回そのSonnetが大幅に強化されました。
まずはここだけ押さえればOKです。
- モデルID: claude-sonnet-4-6
- コンテキスト: 200Kトークン(ベータで1M対応)
- 最大出力: 64Kトークン
- 速度区分: Fast(Claudeモデル内の相対評価)
- 知識カットオフ: 2025年5月まで信頼可能
- 利用料金: 4.5と同じ据え置き価格
claude.aiでは、無料(Free)プランと有料(Pro)プランのデフォルトモデルがSonnet 4.6に切り替わっています。つまり、いま普通にClaudeを使っている人は、すでにSonnet 4.6を触っている可能性が高いです。
結論:4.5は「作れる」、4.6は「プロダクト水準で実装できる」
先に結論をお伝えします。
Claude Sonnet 4.5と4.6の差は、精度が数%上がったとか、レスポンスが速くなったとか、そういう話ではありません。アウトプットの「実装の質」が変わったというのが、実機検証を通じた率直な感想です。
同じプロンプトでToDoアプリの実装を依頼したところ——
- 4.5: 必要な機能が揃った、シンプルなToDoアプリ
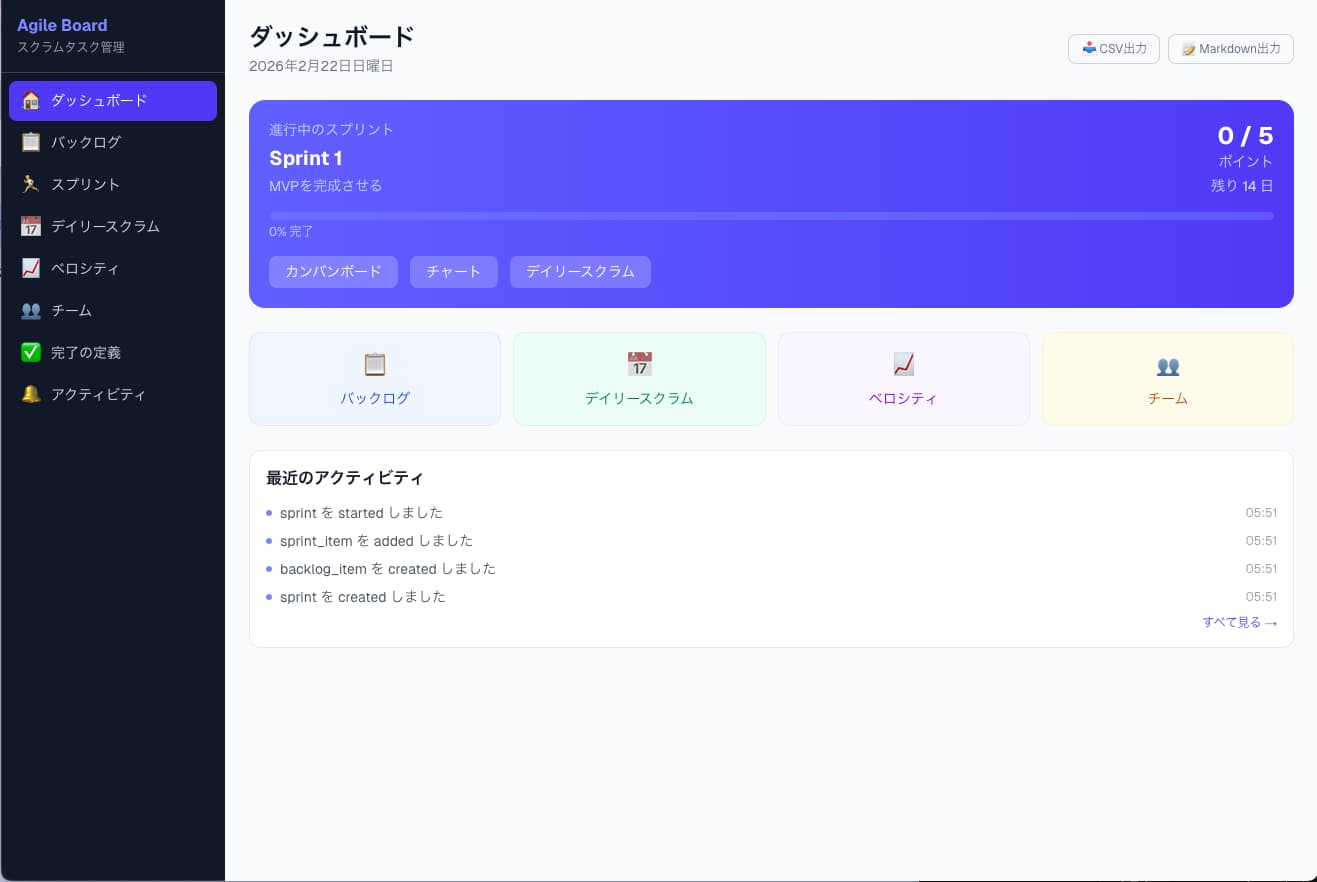
- 4.6: サイドバーにダッシュボード・バックログ・スプリント・ベロシティが並ぶ、軽量アジャイル管理ツール
4.5が「ちゃんと作れるアウトプット」だとすれば、4.6は「実務投入にかなり近いアウトプット」。この差は、使ってみると体感としてはっきりわかります。
このあと、具体的にどこが違ったのか、実機検証のフローと結果を掘り下げていきます。
実機検証:4.5 → 4.6で何が変わったのか
検証環境はClaude CodeとGitHub Copilotの2つ。同一プロンプトで、4.5と4.6それぞれにToDoアプリを作らせました。
検証フロー
今回の検証は、以前Codex検証でも使用したToDoアプリ開発フローを踏襲しました。
事前にスクラムの前提知識をまとめたファイル(modal_md/gemini3-1/スクラムについて.md)を用意し、Web検索なしでも文脈を渡せる状態にしてから検証を開始しました。
実際に投げた指示は次の2段階です。
タスク1:要件定義
アジャイル寄りな内容のタスクアプリを作りたい
タスク管理にどんな機能が必要なのかまとめてmdを作って
タスク2:実装
mdの内容で実装をしてください
docker + next.js + sqliteの構成でアプリを作り切って欲しいです
設計→実装の2段階で検証しています。
4.6のアウトプット(Claude Code):「要件を超えて設計してくる」
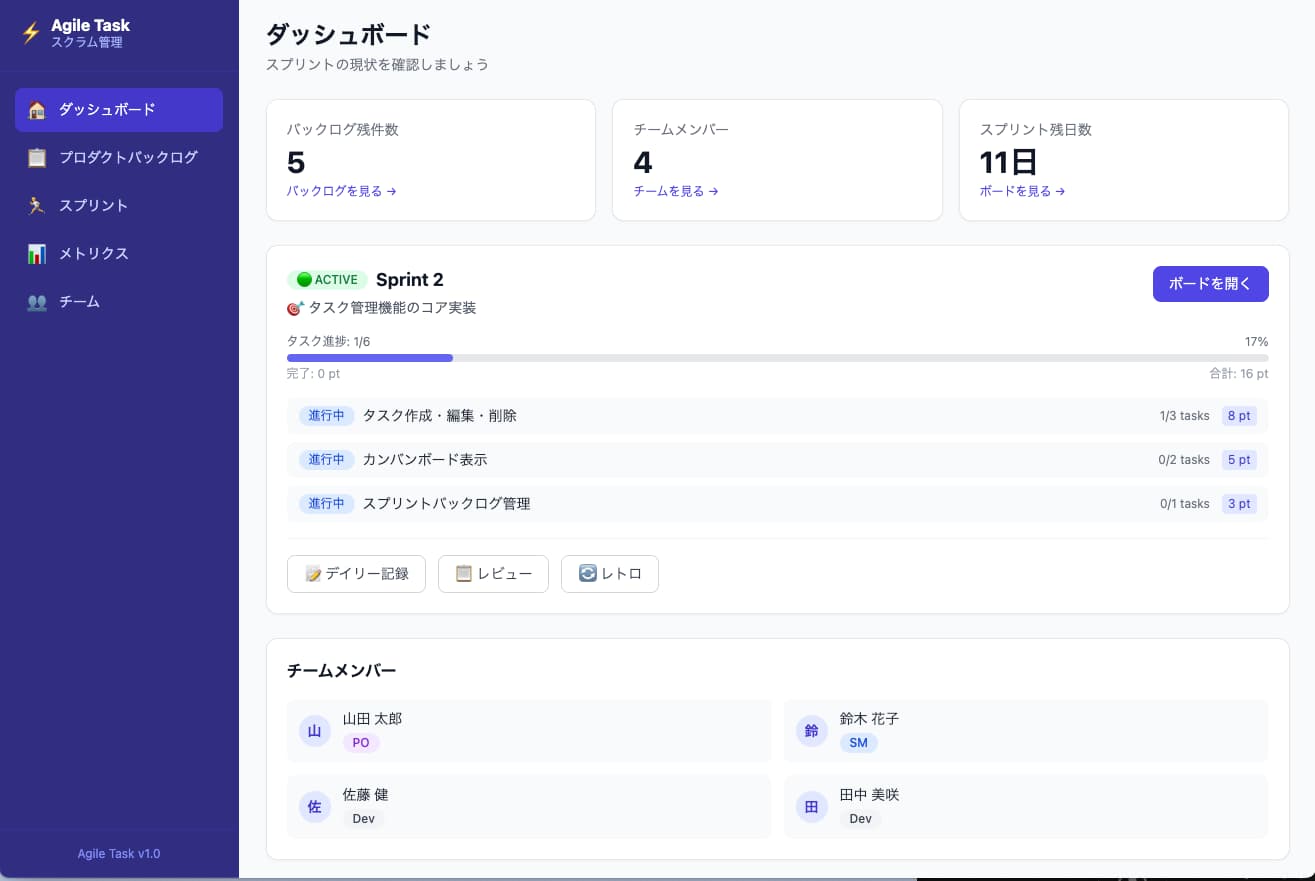
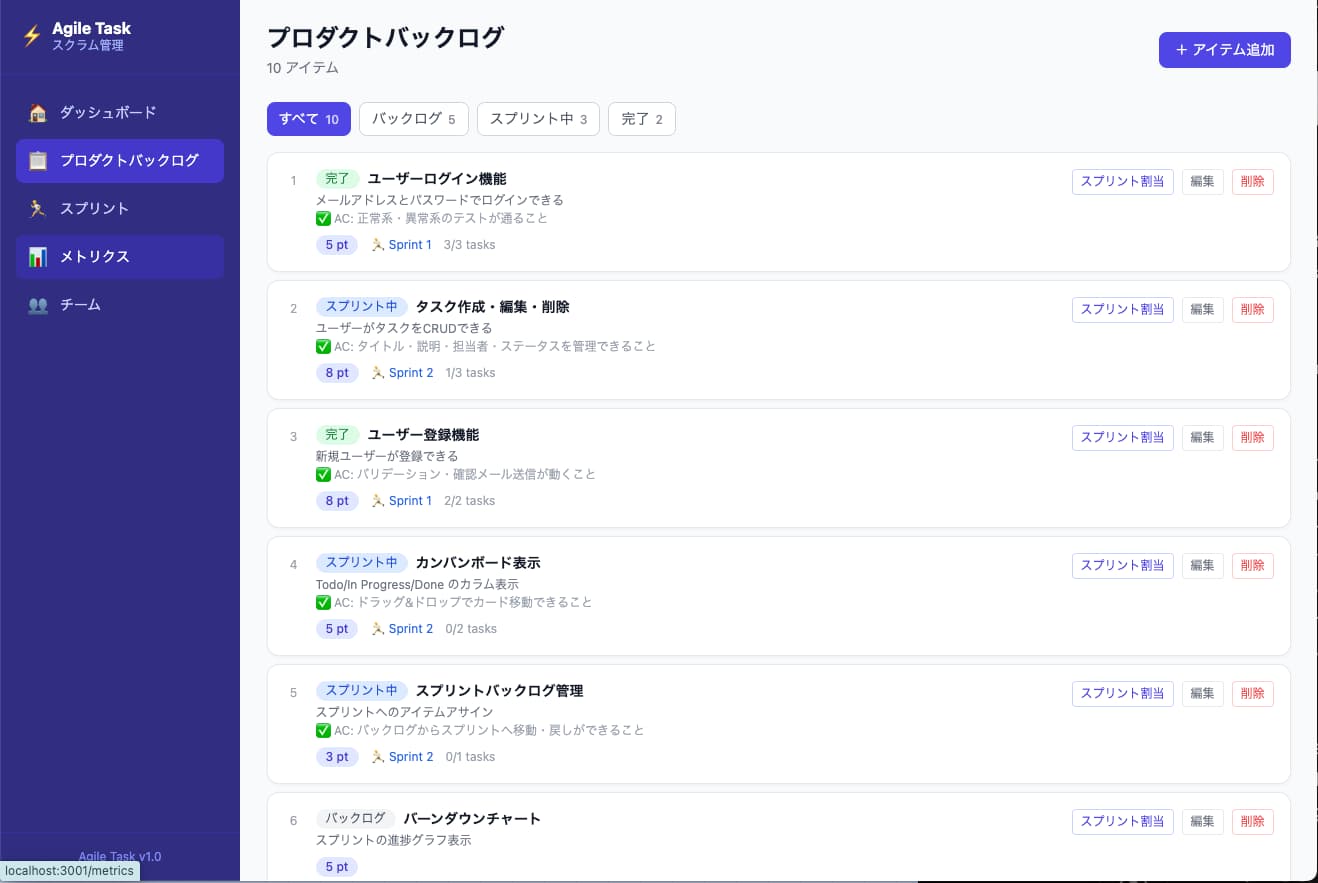
ここで、重要な事実を先に共有します。
要件定義フェーズで生成されたドキュメントを見ると、Claude Code版(4.6)はGitHub Copilot版(4.5)に比べてシンプルです。10セクション構成で、機能の総量も4.5より少ない。「詳細な仕様書を出してくる」という意味では、4.5のほうが丁寧にも見える。
ところが実装では逆転します。
生成されたアプリの画面を並べると、Claude Code版(4.6)のほうが、圧倒的に細かく作り込まれているんです。
具体的には:
- サイドバーがアジャイル前提で整理されている(ダッシュボード / バックログ / スプリント / ベロシティ / チーム / 完了の定義)
- ダッシュボードにスプリントのヒーローカード(0/5ポイント・残14日・進捗率を一画面に集約)
- 「いまチームが何を見るべきか」を判断した情報設計(ポイント残量・残日数・進捗率)
- Reviewを含むカンバン構成など、実務寄りの意思決定が反映されている
- スプリント詳細・バックログ・ベロシティなど、複数画面に渡る遷移設計
要件には書いていないことを、実装に入れてくる。
これが4.6で起きていることの本質です。ToDoアプリというより、軽量なアジャイル管理SaaSに近い仕上がりです。
4.5のアウトプット(GitHub Copilot):「作れる」レベル

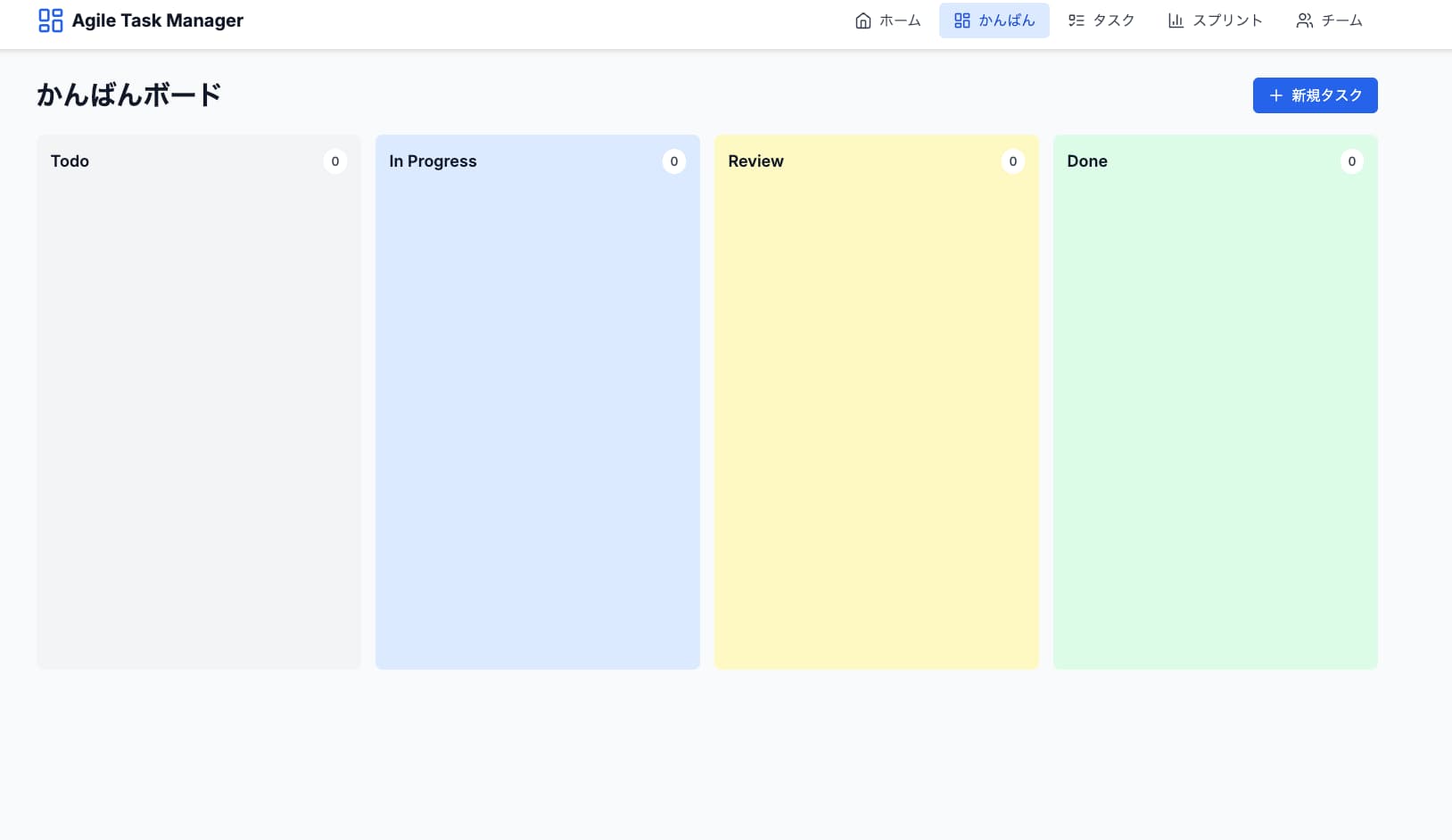
一方で4.5のアウトプットは以下の通りでした。
- 必要機能は揃っている
- 構成はシンプル
- 画面展開の広がりは限定的
- 情報密度が4.6より薄い
成立はしているものの、実装の深さ・スケール感は4.6に劣ります。まさに「作れる」レベルのアウトプットです。
4.6が強いと感じた3つの理由
比較して、4.6が明確に一段上の完成度だと感じた理由は以下の3点です。
1. 情報設計の深さ
スプリント残日数、ポイント進捗、チーム構成、ベロシティなど、利用イメージを具体的に想定した情報設計がなされていました。プロンプトで細かく指定しなくても、モデル側で「アジャイル開発ならこの情報が必要だろう」と判断して補ってくれます。4.5にはこの「利用シーンの想像力」が欠けていました。
2. パーツ単位の完成度
バッジ、ステータスラベル、進捗バー、ポイント表示、サイドバーのアクティブ状態など、細部がしっかりと揃っています。4.5は「成立している」レベルですが、4.6は「整っている」レベルです。
3. スケール感
画面数が多く、管理者視点も含まれており、情報が階層的に整理されています。小規模SaaSレベルの構造を1回のプロンプトで生成してくるのが4.6の実力です。
なぜ「シンプルな要件」から「豊かな実装」が生まれるのか
実はここが、4.5と4.6の差を理解するうえで最もコアな部分です。
今回の検証では3パターン(4.5 / Copilot版4.6 / Claude Code版4.6)の要件ドキュメントが生成されましたが、それぞれの設計思想を比較するとこんな構図が見えてきます。
| 観点 | 4.5(Copilot) | 4.6(Copilot) | 4.6(Claude Code) |
|---|---|---|---|
| 要件の生成スタイル | 14セクション・3フェーズで網羅的 | 9セクション・MVP中心に簡潔 | 10セクション・スクラムの本質から逆算 |
| 設計の起点 | 「何の機能が必要か」 | 「何が最小限で済むか」 | 「ユーザーはこのアプリで何をするか」 |
| 実装の完成度 | 機能が揃っている | 機能が整理されている | 機能を超えた、体験が設計されている |
4.5は「要件に書かれたものを実装する」という発想です。チェックリストを埋めるように機能を並べていく。
4.6(Claude Code)は違います。「このアプリを使う人は、最初に何を見るか。次に何をするか」という使い手の時間軸から逆算して設計しています。
だから、要件に「スプリント管理」と一言書いてあるだけでも、実装に落とすときに「スプリント一覧・ゴール表示・進捗ヒーローカード」まで自動補完してくる。「チーム管理」とあれば、メンバーアイコン・ロール・キャパシティ表示まで追加してくる。
要件を仕様書として読むのではなく、ユーザーシーンとして読んでいる——これが4.6の実装力の正体です。
公式ベンチマークの「SWE-bench 79.6%」にこの質は含まれていません。「何を実装するかを自分で判断する能力」は、コーディング精度とは別軸のものだからです。
ツール差(Claude Code vs GitHub Copilot)はどうだったか
参考までに、GitHub Copilotで4.6を使った場合のアウトプットも載せておきます。
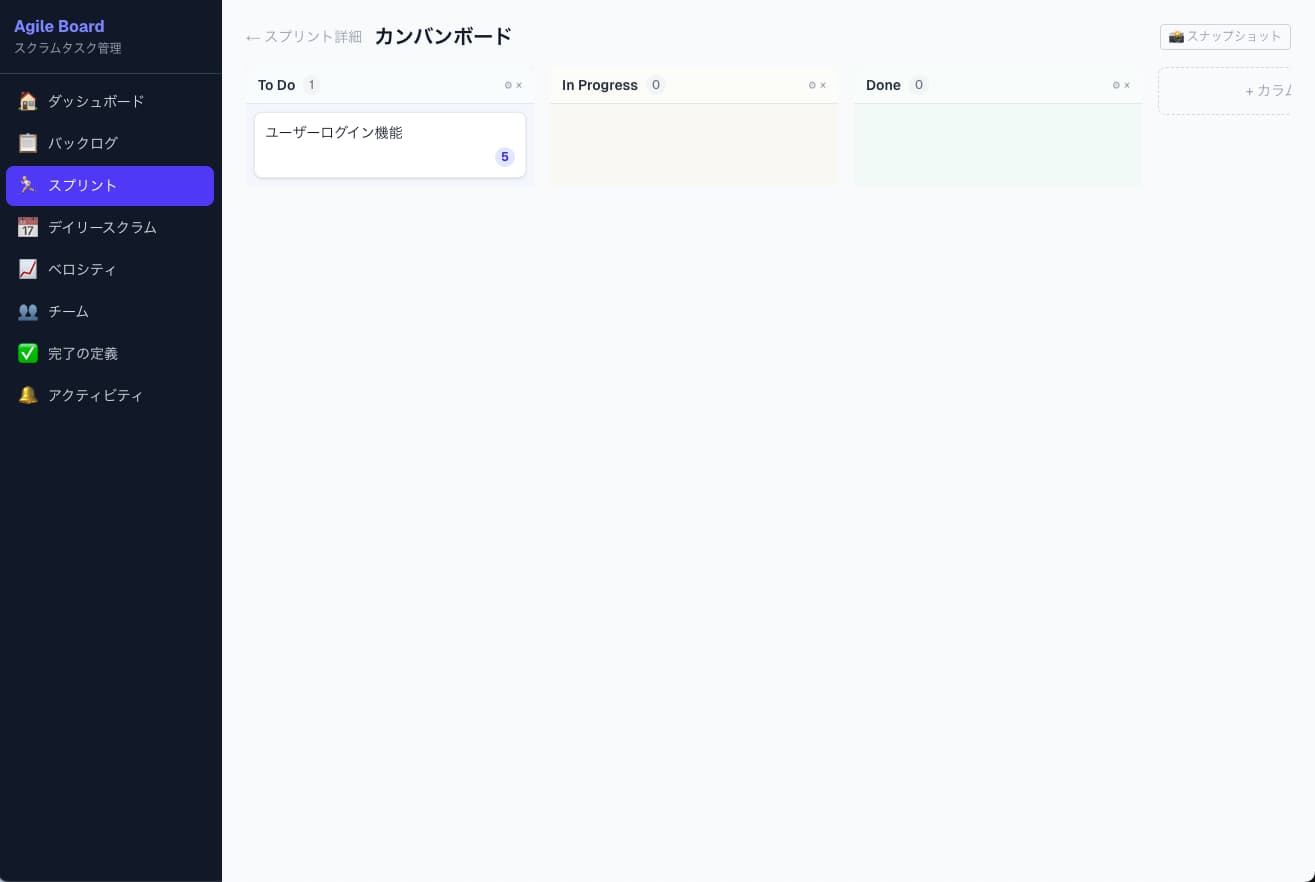
結論から言うと、ツールの差はほぼなかったです。
カラーの傾向やUIトーンの違い、レイアウトの微差はありましたが、本質的な完成度は同等でした。アウトプットの品質を決めているのは、ツールではなくモデル世代の差です。
公式ベンチマークで見る、4.6の実力
体感だけでなく、数字でも確認しておきましょう。公式のシステムカードに記載されている主要ベンチマークです。
| ベンチマーク | Sonnet 4.6 | 参考:Opus 4.6 | ひとこと |
|---|---|---|---|
| SWE-bench Verified(コーディング) | 79.6% | 80.8% | Opusとの差はわずか1.2pt |
| OSWorld-Verified(PC操作) | 72.5% | 72.7% | ほぼ同等、差は0.2pt |
| Terminal-Bench 2.0(端末操作) | 59.1% | — | 自律的な端末操作 |
| GPQA Diamond(科学QA) | 89.9% | — | 高度な推論力 |
| Finance Agent(金融分析) | 63.3% | 60.1% | Opusを上回る |
注目すべきは、OSWorldでOpus 4.6との差がわずか0.2ポイントしかないこと。そしてFinance Agentでは逆転している点です。
ただし、未知の問題を解く力(ARC-AGI-2)ではOpus 4.6が68.8%に対してSonnet 4.6は58.3%と、約10ポイントの差があります。「前例のない問題を深く考える」タスクでは、まだOpusに軍配が上がります。
つまり、日常的なコーディングや業務タスクならSonnet 4.6で十分。深い推論や未知の課題に挑むときはOpus、という使い分けが現実的です。
Claude Sonnet 4.6の料金
料金はSonnet 4.5から据え置きです。ここは素直にうれしいポイント。
| 項目 | 料金(100万トークンあたり) |
|---|---|
| 入力(200K以下) | $3(約460円) |
| 出力(200K以下) | $15(約2,300円) |
| 入力(200K超・長文脈) | $6(2倍) |
| 出力(200K超・長文脈) | $22.50(1.5倍) |
参考までに、Opus 4.6は入力$15・出力$75。Sonnet 4.6はOpusの5分の1のコストです。
先ほどのベンチマークを踏まえると、多くの業務シーンで「5分の1の価格で、ほぼ同等の品質」が手に入ることになります。
無料で使えるの?
はい。claude.aiのFreeプランでSonnet 4.6がデフォルトモデルとして使えます。アカウントを作るだけでOKです。
有料プランの場合は、Proが月額$20(年額なら月$17相当)、Maxが月額$100〜。Proでも十分に活用できるので、まずはFreeかProから始めるのが現実的です。
Sonnet 4.6が使える環境
すでに主要なツール・プラットフォームで使えるようになっています。
- claude.ai: 全プラン対応(Free/Pro/Max)
- Claude Code: v2.1.45でSonnet 4.6サポートを追加
- GitHub Copilot: GAロールアウト済み(VS Code、github.com等)
- Cursor: モデル一覧にClaude 4.6 Sonnetの記載あり
- AWS Kiro: Pro/Pro+/Powerで利用可能
- Amazon Bedrock / Google Cloud Vertex AI: クラウド経由で対応
普段使っているツールから、モデル選択でSonnet 4.6を指定するだけです。
ChatGPTやGeminiと比べてどうなのか
「結局、ChatGPTやGeminiと比べてどうなの?」は多くの方が気になるところだと思います。
公式発表のベンチマーク比較によると、Sonnet 4.6はGemini 3 ProやGPT-5.2を複数のテストで上回っています。特にOffice tasks(PC操作を伴う事務作業)では全モデル中トップのスコアでした。
ただし、これはあくまでベンチマークの話です。実際の使い勝手は用途によって変わります。
個人的な実感としては、コーディングとプロダクト設計の文脈理解はClaudeが一歩抜けている印象です。一方で、最新ニュースへのアクセスはGeminiに強みがあり、ChatGPTは汎用的な対話で安定感があります。
「どれが最強か」ではなく「何に使うか」で選ぶ。これが2026年のAI選びだと思っています。
知っておきたい注意点
良いことばかり書いても信用できないと思うので、注意点も正直に共有します。
速度が遅いという声がある
リリース直後から「4.5に比べて遅い」「簡単なタスクでも数分かかる」という報告が複数出ています。
原因は2つ考えられます。ひとつはリリース直後のアクセス集中。もうひとつは、4.6で導入されたAdaptive Thinking(タスクの難易度に応じて推論の深さを自動調整する機能)がデフォルトで「高」になっていること。簡単な質問に対してもモデルが深く考えようとするため、レイテンシが増えるケースがあるようです。
創造的なタスクはやや苦手かも
口コミを見ると、「回答が冷たく短い」「創造的なタスクは物足りない」という声もあります。コーディングやデータ分析に特化して進化した分、文学的な表現力はOpusのほうが上かもしれません。
全員がSonnet 4.6にすべきとは限らない
前例のない複雑な問題に取り組む場合や、深い推論が必要な研究用途では、Opus 4.6のほうが適しています。Sonnet 4.6は「日常業務・コーディング・エージェント運用」で最もコスパが高いモデルであって、万能モデルではありません。
迷ったときの判断軸はシンプルです。
- 日常業務・コーディング・定型分析 → Sonnet 4.6
- 深い思考・未知の問題・壁打ち → Opus 4.6
- まだ決められない → まずSonnet 4.6を無料で試す
4.6で変わったこと、変わらなかったこと
最後に、検証を通じて感じたことを整理します。
変わったこと:
- 「コードを書く」だけでなく「プロダクト水準で実装する」力がついた
- UIの細部まで作り込む完成度が上がった
- 単一ページではなく、アプリ全体の構造を考えて出力するようになった
- Opusとの性能差がほぼなくなった領域がある
- 価格は据え置きのまま、性能が大幅に向上した
変わらなかったこと:
- ツール(Claude Code vs Copilot)の差よりモデル世代の差のほうが大きい
- 深い推論タスクではOpusが依然として強い
- 長文脈(1M)はベータのまま、条件つき
まとめ:まずは無料で、一度触ってみてください
Claude Sonnet 4.6は、Sonnetシリーズの「妥協の選択肢」から「積極的な選択肢」への転換点です。
Opusの5分の1の価格で、多くの場面でOpusに匹敵する。コーディング、PC操作、金融分析では一部Opusを超える。これは公式のベンチマークが示している事実です。
そして実機で検証してみると、数値以上に「実装の深さ」「パーツの完成度」「構造のスケール感」が進化していることがわかります。4.5 → 4.6は、単なるバージョンアップではなく実装レベルの世代交代でした。
claude.aiの無料プランですぐに使えるので、まずは普段の業務で一度試してみるのが一番早いと思います。「この資料の要点をまとめて」「この仕様でUIを考えて」——それだけで、4.5との違いは体感できるはずです。
関連記事
リリースの近かったgemini 3.1 proについても記事をあげているので、ぜひ読んでいただけると嬉しいです