Gemini 3.1 Pro 徹底解説|技術仕様・ベンチマーク・Antigravity & Copilot 実践検証【2026年最新】
「Copilotで使ってみたけど、なんか思ったより動きが鈍い。自分の使い方が悪いのか、モデルの問題なのか判断できない」
「AntigravityとCopilotで同じモデルを使って、なぜここまで出力の質が違うのか」
「スペックは凄そうだけど、自分のプロジェクトで本当に使えるのかがわからない」
こういう疑問を持ったままモデル選択を続けているエンジニアは多いと思います。自分もそのひとりでした。
この記事では、技術仕様とベンチマーク数値を一次ソースから整理した上で、AntigravityとGitHub Copilotで実際にWebアプリを作り切った検証結果をそのまま書いています。スペックと実感の両方を並べて読めるようにしました。
「技術仕様の確認」→「ベンチマーク数値の読み方」→「価格と試算」→「thinking_levelの制御」→「実際の検証フローと結果(Antigravity / Copilot / Gemini 3)」→「ツール別の使い分け」→「実務ポジション整理」の順で解説します。
Gemini 3.1 Proとは:技術仕様をひととおりおさえる
Gemini 3.1 ProはGoogleが2026年2月19日に"プレビュー"として公開した、Gemini 3 Proの改良版です。推論・エージェント実行・SWE(ソフトウェアエンジニアリング)品質の向上を主眼に設計されています。
利用できるチャネルは、Gemini API(AI Studio)・Gemini CLI・Antigravity・Android Studio・Vertex AI・Gemini Enterpriseと幅広く展開されています。
仕様の要点
| 項目 | 仕様 |
|---|---|
| 最大入力トークン | 1,048,576(約104万) |
| 最大出力トークン | 65,536 |
| 入力モダリティ | テキスト・コード・画像・音声・動画・PDF |
| 出力モダリティ | テキストのみ |
| 知識カットオフ | 2025年1月 |
アーキテクチャはsparse MoE Transformerです。入力トークンごとに複数の「専門家(experts)」へ動的にルーティングする設計で、計算コストを抑えつつ表現力を確保する構造です。ただしパラメータ数は公式非公開のため、規模感の直接比較はできません。
知識カットオフが2025年1月という点は運用で効いてきます。長いコンテキストに最新情報を渡しても、モデル自体の知識が更新されるわけではありません。最新APIの仕様や直近のリリース情報を扱うときは、ドキュメントや検索結果をコンテキストに含めて渡す必要があります。
Live APIと音声生成は現バージョン(Preview)では非対応です。これらが必要な用途は別モデルと組み合わせる構成にする必要があります。この記事では後述するCI/CD統合などのコーディング用途に絞って評価しています。
AI駆動開発の文脈での読み方
ARC-AGI-2の77.1%(Gemini 3比で+46pt)は目立ちますが、実務で効いてくるのはSWE-Bench・Terminal-Bench・APEX-Agentsが同時に伸びている点です。
- SWE-Bench 80.6%:コード修正→テスト通過まで含めた実装精度
- Terminal-Bench 68.5%:bash等のツール操作精度
- APEX-Agents 33.5%:複数ステップにわたるエージェント実行の安定性
edit→test→fixのループをツールを絡めながら多段実行する場面で崩れにくい、という解釈が成立します。GitHub Copilotが公式に「edit-then-test loopでの効率とツール精度」を強調していることとも一致しています。
一方、Terminal-BenchはGPT-5.3-Codexに届いていないなど、全指標でトップではありません。「得意な軸がある」という認識で使う方が実務では正確です。
API価格(2026年時点)
| 項目 | 無料枠 | 有料(100万トークンあたり / USD) |
|---|---|---|
| 入力価格 | 利用不可 | $2.00(≤ 200,000 tok)/ $4.00(> 200,000 tok) |
| 出力価格(思考トークン含む) | 利用不可 | $12.00(≤ 200,000 tok)/ $18.00(> 200,000 tok) |
| コンテキストキャッシュ投入 | 利用不可 | $0.20(≤ 200,000 tok)/ $0.40(> 200,000 tok) |
| キャッシュストレージ | 利用不可 | $4.50 / 1M tok / 時間 |
| Google検索グラウンディング | 利用不可 | 月5,000プロンプト無料。超過:$14 / 1,000クエリ |
| Googleマップグラウンディング | 利用不可 | 利用不可 |
| プロダクト改善への利用 | あり | なし |
料金は変更される場合があります。最新情報は必ず公式ページでご確認ください。
簡易コスト試算(≤200kコンテキスト)
PRレビュー1回分を想定した場合(入力20,000tok / 出力4,000tok):
- 入力:$2 × 0.02 = $0.040
- 出力:$12 × 0.004 = $0.048
- 合計:約$0.088 / 回(≈13円)
thinking tokenが出力側に加算される点に注意が必要です。後述のthinking_levelをHIGHにすると思考トークンが増え、出力コストが上がります。
GitHub Copilot経由の場合はプレミアムリクエストの乗数がGemini 3.1 Proは「1」に設定されています。トークン課金への直接換算はできませんが、乗数1はCopilot料金体系の中ではノーマルです。
thinking_levelで変わる速度と品質のトレードオフ
Gemini 3.1 Pro固有の運用パラメータとして thinking_level があります。Gemini 3.1 ProではGemini 3 ProになかったMEDIUMが追加され、LOW / MEDIUM / HIGHの3段階で思考の深さを制御できます。
| レベル | 特性 | 向いている用途 |
|---|---|---|
| LOW | レイテンシ最短、思考最小 | IDEのリアルタイム補完・チャット |
| MEDIUM | 速度と品質のバランス | コードレビュー・設計相談 |
| HIGH | 思考最大、TTFT大きく増加 | CI/CDでのバグ修正・自律エージェント |
デフォルトはTHINKINGがONです。IDEのインタラクションで快適に使うなら、LOWかMEDIUMを起点にするのが現実的です。HIGHにするとTTFT(初回トークン到達時間)が体感できるレベルで遅くなります。
CI/CDで自律エージェントとして動かすなら逆にHIGHが合います。「IDE側はMEDIUM、CI/CD側はHIGH」という使い分けが、コストとパフォーマンスのバランスを取る実務的な設定です。
もう一点、マルチターン+ツール呼び出しが絡む実装では thought signatureを次のターンへ引き回す設計が必要になります。エージェントを組む場合は状態管理の要件として把握しておく必要があります。
今回の検証は両ツールともLow / Fast Mode相当での実施です。thinking_levelをHIGHにした場合の挙動は検証できていないため、その点は限界として明記しておきます。
実際にやった検証内容(フローと前提)
技術仕様とベンチの確認が終わったところで、実際に手を動かした検証の話に入ります。
検証フロー
今回の検証は、以前Codex検証でも使用したToDoアプリ開発フローを踏襲しました。
事前にスクラムの前提知識をまとめたファイル(modal_md/gemini3-1/スクラムについて.md)を用意し、Web検索なしでも文脈を渡せる状態にしてから検証を開始しました。
実際に投げた指示は次の2段階です。
タスク1:要件定義
アジャイル寄りな内容のタスクアプリを作りたい
タスク管理にどんな機能が必要なのかまとめてmdを作って
タスク2:実装
mdの内容で実装をしてください
docker + next.js + sqliteの構成でアプリを作り切って欲しいです
設計→実装の2段階で検証しています。
検証の前提として
今回の検証は、以下の条件で実施しています。
| ツール | 実行モード | 思考レベル (thinking_level) | 備考 |
|---|---|---|---|
| Antigravity | Fast Mode | Low | Planning Mode, Highは環境上うまく動作せず未検証 |
| GitHub Copilot | エージェントモード | (設定なし) | プランモードは未使用 |
なお、GitHub Copilotで利用できるGemini 3.1 Proには、現時点でthinking_level(Low / Medium / High)の設定項目はありません。そのため、Copilot側はデフォルトの状態で検証を行っています。
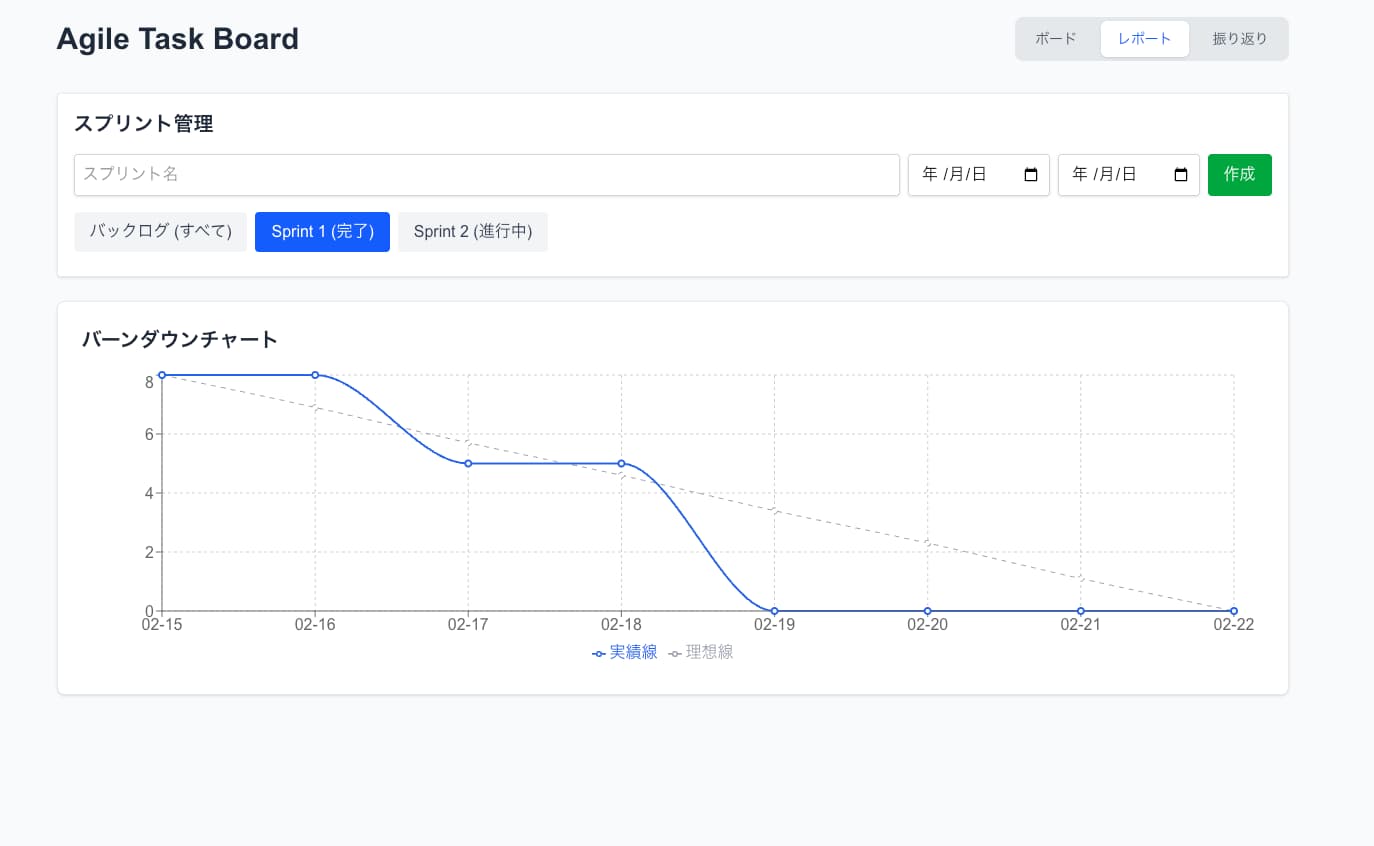
検証結果1:Antigravity × Gemini 3.1 Pro
AntigravityはGoogleが提供するAI開発ツールで、同じGoogleのモデルであるGemini 3.1 Proとの親和性に期待して検証しました。
結論から言うと、後述するCopilotで使ったときよりも全体的に調子が良い印象でした。UIやデザイン生成の見た目も自然で、ぱっと見の完成度も高いです。
実際に出力されたのはこういったUIです。
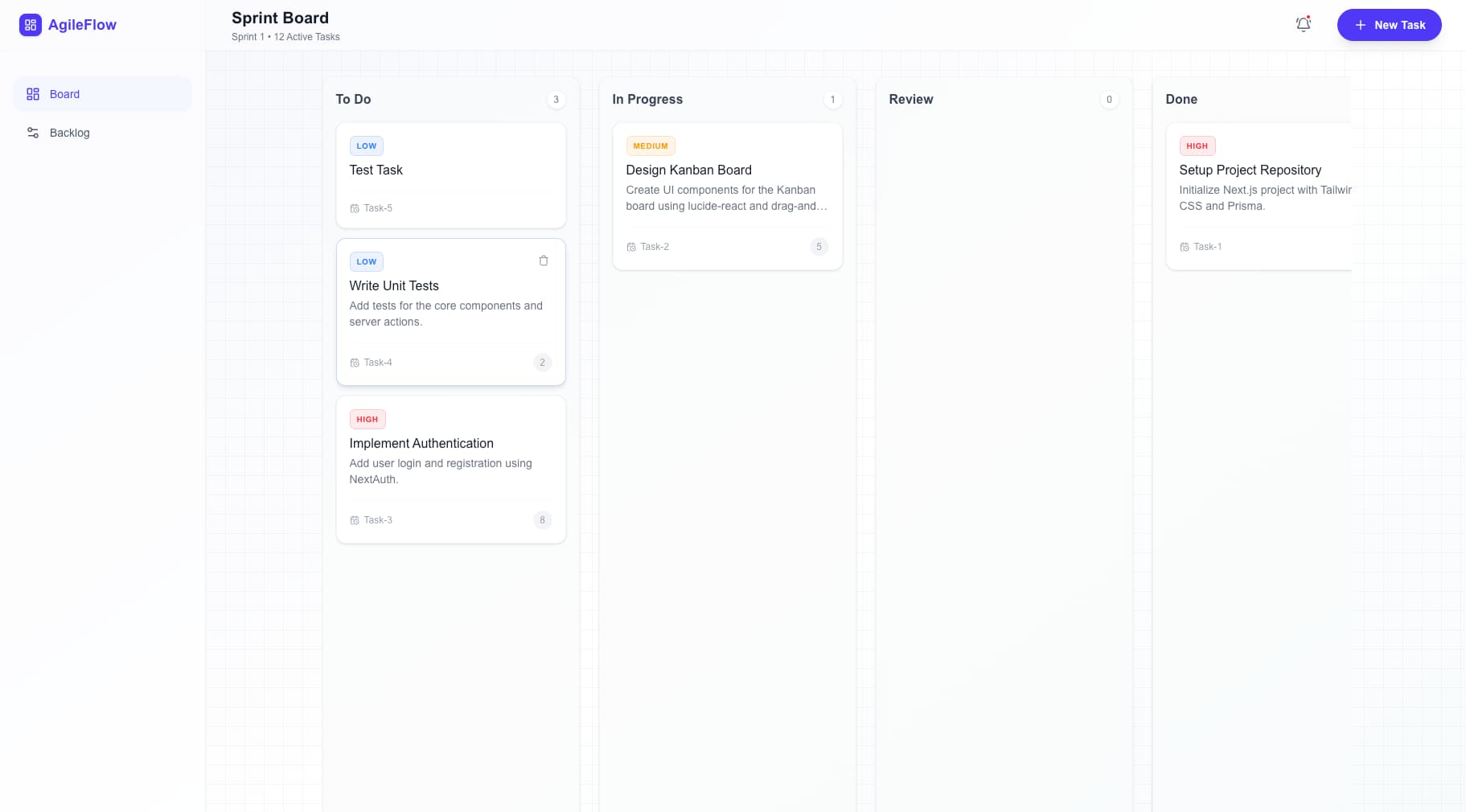
カンバンボードとして見ると、カラム構成(To Do / In Progress / Review / Done)が自然に揃っていて、タスクカードの情報密度もちょうど良い。優先度バッジ(HIGH / MEDIUM / LOW)の色分けも直感的で、サイドバーのナビゲーションも含めてプロダクトとして十分成立するレベルのUIが一発で出てきました。
一方で気になった点もあります。出力物にバグが残るケースがやや多めで、一発で完全にきれいな状態になる割合は高くありませんでした。また、機能の網羅性(MECEさ)にも課題が残る印象です。要件定義で定義した機能が漏れなく実装されているかというと、そうとは言いにくく、スコープが自然に絞られてしまう傾向がありました。
ただし、修正指示を出して回せばきちんと直してくれるため、致命的というよりは許容範囲内です。「止まる」というよりは、初回出力に荒さが残りやすいという表現が近い。修正ループで収束する動きはしてくれます。
補足で、最初はhighでやろうと思ったんですが、highはいつまで経っても動きませんでした。
たまたま調子が悪かったのかもですが、highにすると精度はもう少し上がると思います。
検証結果2:GitHub Copilot × Gemini 3.1 Pro
次に、GitHub Copilotでの検証結果です。
タスク2の初期出力(コア機能のみ)
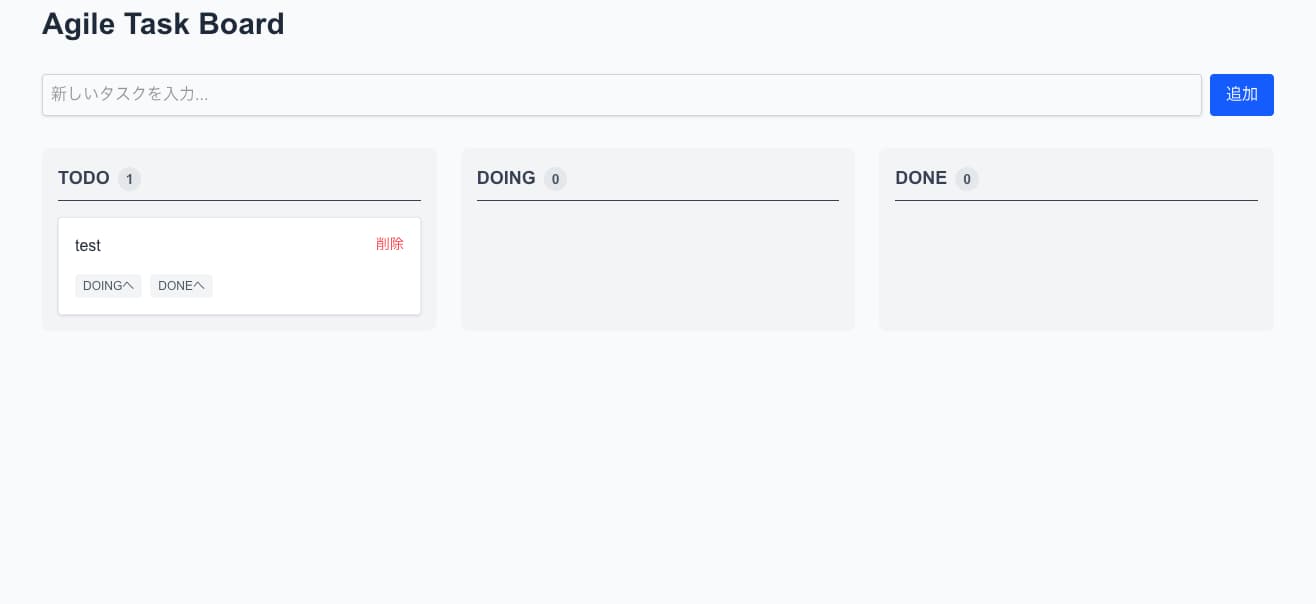
「全部作り切って」と明確に書いているにもかかわらず、コア機能のみ実装し、段階的に安全に分割するという挙動を取りました。実行時間が10分もないくらいで止まっていたので、ボリューム感はかなり抑えめです。
そのため、次の追加指示が必要になりました。
本来はここまでだけどコア機能だけだったので
あなたが満足するところまで突き詰めて作り切って欲しい
追加指示後の出力(完全実装)
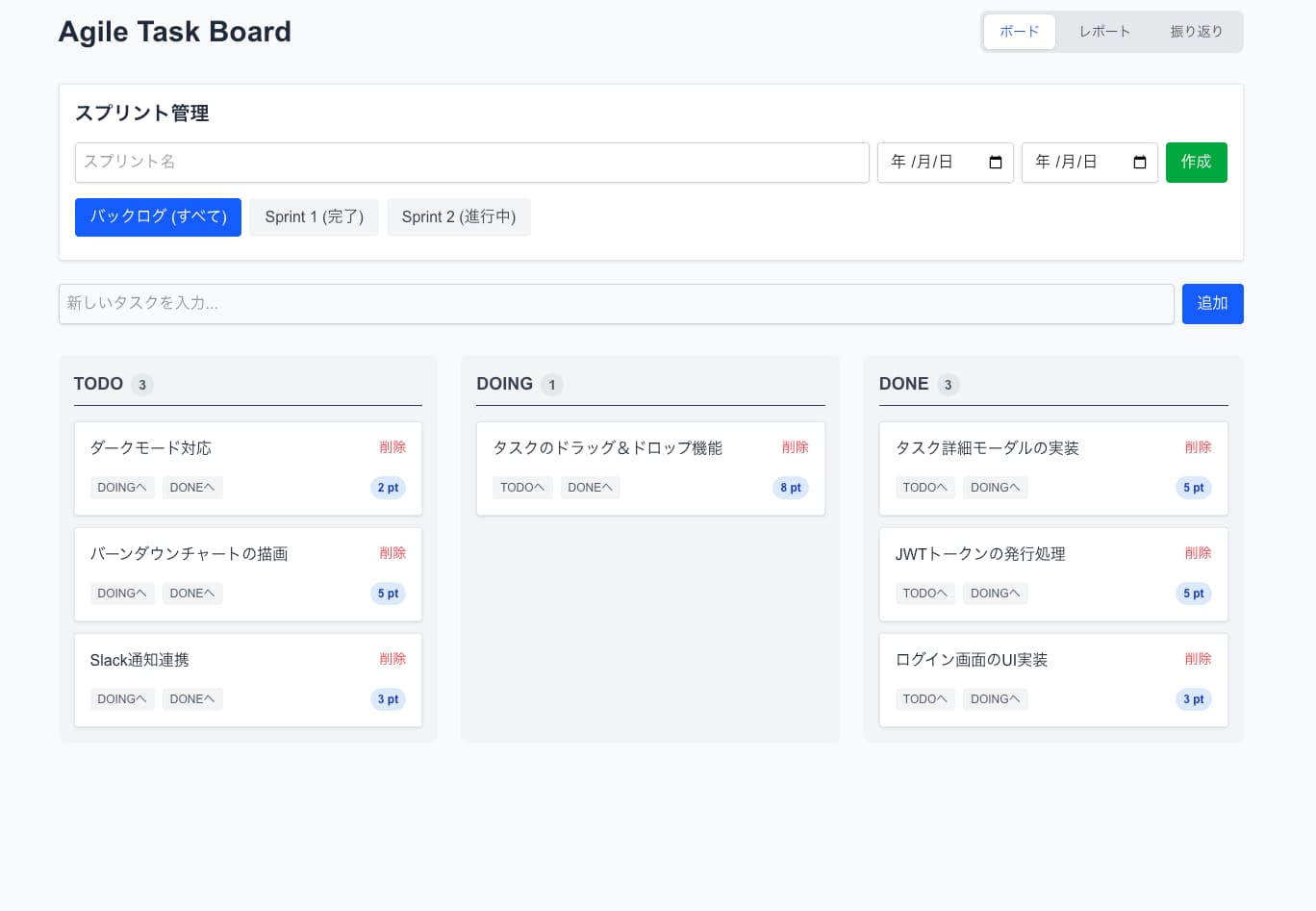
良かった点:UIの完成度はかなり高い
出力されたUIは非常にモダンでした。余白設計が自然、シンプルで使いやすい構成、実務アプリとして成立するデザインというレベルで出てきます。
今回のToDoアプリ検証に限らず、他の場面でもUIとして実務ベースで使っていますが、ここはかなり実感として良いです。余白や情報の置き方が破綻しにくく、最後の見た目を整える工程で頼れる場面が多い印象でした。
スペック面で言えば、SWE-Bench 80.6%という数値が「UI実装の精度の高さ」として出てきているのかもしれません。コードが壊れにくい、ロジックが一貫している、という安定感はこの数値と整合する感覚があります。
気になった点:従順さとミニマリスト気質
モデル側が「無理をしない」実装を優先しているように見えます。堅実とも言えますが、ユーザーの強い指示を曲げる傾向とも言えます。
もう一つ気づいたのが、ミニマリスト気質です。余計なものを出力しない、削ぎ落としたアウトプットを好む傾向があります。UIの仕上がりがすっきりモダンになるのはこの気質の良い面で、個人的には好みでもあります。
ただ、バイブコーディング的に「とりあえず全部生やして」という使い方とは相性が悪い。スコープを絞って丁寧に仕上げる使い方のほうが、このモデルの気質に合っています。
「全指示を完全に受け取って最大出力を出す」という動きを期待すると、ClaudeやGPTのほうが素直に動くことが多いです。Gemini 3.1 Proへの指示は、曖昧な大きさで投げるより範囲を絞って明確にした方が精度が出ます。
正直なところ、まだ自分がこのモデルを使いこなせていない感もかなり強いです。「Gemini 3.1 Proの限界」ではなく「現時点での自分の検証の限界」として見てもらえると助かります。
検証結果3:Gemini 3(前モデル)の場合
3.1の検証にあたって、比較対象として前モデルのGemini 3も同じフローで試しています。
試した結果を正直に言うと、単体で完成形まで持っていくのが難しかったです。動くプロダクトとして成立させるところまで安定せず、実務ラインに乗る手前で止まることが多い印象でした。
Gemini 3での実装結果

これは使い方の問題の可能性も否定できませんが、この検証ではそういう結果でした。3.1との差分を見るための比較起点として整理しています。
ツール別比較:Copilot・Antigravity・Cursorの使い分け
同じGemini 3.1 Proでも、使うツールで体験がかなり変わります。現時点での整理を書いておきます。
| ツール | 特性 | Gemini 3.1 Proとの相性 | 課金方式 |
|---|---|---|---|
| GitHub Copilot | VS Code統合、モデル切替可能 | edit-then-testは得意。UIは相性が出る印象 | プレミアムリクエスト乗数1 |
| Antigravity | Google純正、UIデザイン生成に強い | 相性が最も良い印象 | 要確認 |
| Cursor | モデル選択幅が広い、エディタ統合 | モデル一覧に掲載あり | 詳細は公式で確認 |
| Gemini CLI | OSSエージェント、CI/CD連携 | 公式推奨の統合経路 | 個人アカウントは無料枠あり |
GitHub CopilotについてはVS Code・Visual Studio・github.com・モバイルのいずれでもモデル選択が可能です。Copilot側の早期テスト所見として「効率的なedit-then-test loop」「高いツール精度」「少ないツール呼び出し回数での解決率」が公式に明記されています。これはSWE-Bench 80.6%やTerminal-Bench 68.5%という数値と整合する部分です。
ただし、自分の検証ではCopilotとの組み合わせで出力の完成度がAntigravityに比べて低めという印象がありました。公式の所見はCI/CDやエージェント寄りの文脈での評価であり、IDEでのUI生成という使い方では差が出た可能性があります。
Gemini CLIはCI/CDへの統合という観点で特に面白い選択肢です。Gemini CLI GitHub Actionsを使うと、Issueトリアージ・PRレビュー・@メンションによるタスク委譲を「リポジトリ内の自律ループ」として構築できます。WIF(鍵レス認証)やコマンド許可リストを備えており、CI/CDでの安全制御も整っています。ここではthinking_level HIGHを使い、重推論が求められる場面で力を発揮させる設計が合います。
結論:問題は性能より「性格」
ここまでの検証を踏まえて整理します。
Gemini 3.1 Proはスペックとして確実に進化しています。SWE-Bench 80.6%・ARC-AGI-2 77.1%という数値は実装精度と推論力の両面で一段上がったことを示しています。UIの仕上げ精度もGemini 3から明確に改善しており、実務ラインに乗る安定感が出てきました。
ただ、実際に使って引っかかったのは性能の話ではありませんでした。性格というか、モデルの振る舞いのクセのほうです。
一言で言うと、「従順さが足りない」。もう少し詳しく言えば、ミニマリスト気質があって、強い指示を出しても自分のペースで動く傾向があります。
良いところ
- UIデザインの完成度は非常に高い
- レイアウトバランスが自然でモダン
- 実行のムラはGemini 3より改善
- ロジック破綻が少なく、生成物の一貫性が高い
気になるところ
- 強い指示を出しても自分の判断で安全側に寄せる
- ミニマルな実装を好む傾向があり、一気に作り切りたい場面では物足りない
- バイブコーディング的なノリでガンガン動かすには向いていない
- 初回出力にバグや機能漏れが残りやすい
ミニマリスト気質自体は好みの問題でもあって、個人的には嫌いじゃないです。ただ「指示したことをそのまま全部やってほしい」という場面では、まだClaudeやGPTのほうが素直に動きます。
2026年時点の実務ポジション整理
用途別にまとめると次のようになります。
| 用途 | おすすめモデル | 理由 |
|---|---|---|
| Web開発 0→1 | Claude | 指示追従性が高く、全体を作り切る力がある |
| 安定した汎用実装 | GPT | 素直な動き、予測しやすい挙動 |
| UI・UXブラッシュアップ | Gemini 3.1 Pro | モダンなレイアウト、余白設計の精度が高い |
| CI/CDエージェント統合 | Gemini 3.1 Pro + Gemini CLI | edit-then-testループとツール精度が強い |
| Gemini 3.1を使うなら | Antigravity推奨 | Copilotより相性が良い印象 |
Gemini 3.1 Proは、最終仕上げの美観調整とCI/CDでのエージェント実行という2つの軸で実力を発揮しやすいモデルです。使うツールはAntigravityが相性良好です。
CI/CDへの統合を真剣に考えるなら、Gemini CLI + thinkinglevel HIGHの組み合わせは公式が推奨する統合経路で、ツール精度のベンチ結果とも整合します。IDEとCI/CDで異なるthinkinglevelを設定する二段構えが、コストと品質のバランスを取る現実的な設計です。
2026年のWeb開発では、UIブラッシュアップ担当としてAntigravityで使うか、CI/CDエージェントとしてGemini CLIで動かすか、いずれかに用途を絞るのが最も効果が出やすい使い方だと感じました。
今日できる一歩: 次にGemini 3.1 Proを使うなら、まずAntigravityで「画面(UI)だけ仕上げて」と役割を限定して投げてみてください。それだけでGemini 3.1 Proの強みが最も効果的に出ます。
関連記事
リリースの近かったsonnet 4.6についても記事をあげているので、ぜひ読んでいただけると嬉しいです