【codex最新モデル】gpt-5.3-codex登場:現役エンジニアが実際に触ってみた(2026年2月)
はじめに
codexモデルに新しい仲間が増えました。「gpt-5.3-codex」です。今回、実際にこのcodexモデルと既存モデルを動かしてみて、どんな違いがあるのかを比べてみました。参考になると嬉しいです。
Codex付きモデルが得意なこと
Codex付きモデルは、既存コードを読んで状況を理解して、変更方針を立てて、実装〜検証まで進めるのが強みです。長文の自然言語を大量に書かせるより、差分・手順・実装タスクみたいな「行動に直結する出力」を前提にすると性能が引き出しやすいタイプです。
- 既存コードの読解(依存関係・意図・副作用の把握)
- 変更点の設計(どのファイルをどう直すかの具体化)
- 実装・リファクタ・テスト追加といった作業遂行
- 保守しやすい堅めのコード生成(安全寄りの判断込み)
GPT-5.2(汎用)が得意なこと
GPT-5.2は、自然言語の理解と整理に長けています。曖昧な要件を合意可能な仕様に落とすことに特化しており、文章主体(企画・仕様・レビュー・ドキュメント)で扱いやすいのが特徴です。もちろんコーディングも十分できますが、特に強いのは「言語化して前に進める」その部分です。
- 仕様の言語化(曖昧さの発見、前提の補完、用語統一)
- 要点整理(論点分解、優先度付け、結論の明確化)
- レビュー観点の列挙(チェックリスト化、抜け漏れ防止)
- 文章の整形(読みやすさ、構造、トーンの調整)
- 調査のたたき台作り(評価軸の設計、比較・選定理由の言語化)
ここが論点:「自然言語の指示駆動開発」はどちらが有利か
- 意図理解(曖昧さを補えるか)
- 指示追従(制約・優先度・出力形式を守れるか)
- 収束性(追加指示の回数が減るか)
OpenAIが語る gpt-5.3-codex の変化点
何が強い?(能力の方向性)
OpenAIの説明によると、5.3-Codexは「単にコードを書く」よりも、コーディング+ターミナル操作+実世界タスクをまとめて高い精度でこなす方向に振ってきたようです。
ブログ側では、主に次の4系統の評価で強みが示されています。
- SWE-Bench Pro:実務寄り・複数言語の厳密評価
- Terminal-Bench 2.0:ターミナル操作を含むエージェント能力
- OSWorld-Verified:OS操作系の実世界タスク
- GDPval:職種横断の知識労働タスク(資料・表計算など成果物作成も含む)
発表ページの付録に掲載されている代表スコアは以下。
- SWE-Bench Pro(公開版):56.8%
- Terminal-Bench 2.0:77.3%
- OSWorld-Verified:64.7%
- GDPval(勝利・引き分け):70.9%
「コードを書く」を越えて、開発ライフサイクル全体を狙う
もう1つ注目すべき点は、支援対象が実装そのものだけではないと明記されていることです。
デバッグ/デプロイ/監視/PRD作成/コピー編集/ユーザーリサーチ/テスト/メトリクス管理など、ソフトウェア開発の周辺業務まで含めて「開発ライフサイクル全体」を支援する位置づけになっています。さらに、スライド作成やスプレッドシート分析のような成果物作成も支援対象に組み込まれています。
25%高速化が効く作業
- 体感として効くのは、往復回数が多いタスク(調査→修正→テスト→PR など)
- 速度改善は「1回の生成が速い」だけでなく、待ち時間の総和が減るタイプの作業ほど効果的です(例:CI失敗の原因追跡→修正→再実行)
ベンチの伸びから見える方向性
- SWE系より、Terminal/OS操作系が強く伸びている
- 「実行込みで完了」に寄せた改善の可能性が高い
安全設計(運用に直結する部分だけ)
- 隔離実行/ネットワーク制御が前提
- チームで揉めやすいのは「外部通信」「認証情報」「書き込み操作」
安全面は「思想」よりも、運用で事故が起きるポイントを先に塞ぐのが重要です。
- ネットワーク:デフォルト遮断 + allowlist(必要なドメインだけ許可)にすると、事故の範囲が限定される
- 認証情報:短命トークン、最小権限、ログ/プロンプトへの露出を避ける(扱いルールの明文化が優先)
- 書き込み:コミット/プッシュ/デプロイ等は「人のゲート」を挟む(少なくとも最初は)
実際に使ってみた:スクラムタスクアプリで比較
「自然言語の指示駆動開発」における各モデルの実力を測るため、スクラム寄りのタスク管理アプリを題材に、要件定義→実装の流れで比較検証してみました。
検証内容
タスク1:要件定義ドキュメントの作成
アジャイル寄りな内容のタスクアプリを作りたい
まず一般的なスクラムのやり方をまとめその上でタスク管理にどんな機能が必要なのかまとめてmdを作って
タスク2:実装
mdの内容で実装をしてください
docker + next.js + sqliteの構成でアプリを作り切って欲しいです
※ toolのwebsearchは有効化しています
要件定義:各モデルの出力を比較
Codex 5.2 の出力
箇条書きベースで機能要件に特化した構成になっています。エンジニア目線では「必要なことは網羅されている」という印象ですが、ドキュメントとしては機械的です。
特徴
- スクラムの役割・イベント・成果物を端的に列挙
- 必要機能を10項目で整理(バックログ管理、スプリント管理、タスクボード…)
- 目的・背景・ユースケースの記述がほぼなし
所感
「仕様を見ての要件だけ」という印象です。エンジニア同士で共有するには使えますが、ステークホルダーへの説明や合意形成には向きません。ドキュメントとしての「読み物」感が弱く、「仕様を箇条書きで固めた」という冷たさが残ります。
役割(Roles)
- プロダクトオーナー(PO): 価値の最大化、プロダクトバックログの優先順位付けと明確化。
- スクラムマスター: スクラムの理解・実践の支援、障害除去、プロセス改善の促進。
- 開発者(Dev Team): インクリメントの設計・実装・テスト・リリースまでの実作業を行う。
イベント(Events)
- スプリント(1〜4週間): 期間内に完成可能な目標を立て、インクリメントを作る。
- スプリントプランニング: スプリントゴールとスプリントバックログを決める。
- デイリースクラム(15分): 進捗・課題・次の作業を共有し、計画を微調整。
- スプリントレビュー: 完成物をステークホルダーに共有しフィードバックを得る。
- スプリントレトロスペクティブ: プロセス改善の振り返りを行う。
成果物(Artifacts)
- プロダクトバックログ: 価値の高い順に並んだ要求・改善・課題の一覧。
- スプリントバックログ: スプリントで実施するタスクと見積り。
- インクリメント: 「完成の定義」を満たす実動可能な成果。
進め方(典型フロー)
1. プロダクトバックログを作成し、優先順位付けする。
2. スプリントプランニングで目標と作業を決める。
3. スプリント中はデイリースクラムで進捗を確認。
4. スプリントレビューで成果と学びを共有。
5. レトロスペクティブで改善点を決め、次に反映。
タスク管理アプリに必要な機能(アジャイル/スクラム寄り)
1. バックログ管理
- プロダクトバックログの作成・編集・優先順位付け(ドラッグ&ドロップ)
- エピック/ユーザーストーリー/タスクの階層構造
- ストーリーポイント・優先度・価値・リスクなどの属性管理
- 受け入れ条件(Acceptance Criteria)の記述
2. スプリント管理
- スプリントの作成・期間設定・目標設定
- スプリントバックログへの取り込み・見積り管理
- スプリント中のスコープ変更管理(追加/削除の履歴)
3. タスクボード(可視化)
- カンバン形式(ToDo / Doing / Done)
- ワークフローのカスタマイズ(列追加・WIP制限)
- タスクの状態変更履歴
4. プランニング支援
- バックログリファインメントの補助(分割/見積り)
- キャパシティ計画(メンバーの稼働率)
- ベロシティの記録と予測
5. 進捗とレポート
- バーンダウン/バーンアップチャート
- ベロシティチャート
- スプリントレポート(完了率・持ち越しタスク)
- リードタイム/サイクルタイムの計測
6. コラボレーション
- コメント・メンション
- ファイル添付・リンク
- 通知(変更/期限/コメント)
7. 完成の定義(DoD)/品質管理
- 完成条件チェックリスト
- テスト状況・レビュー状況のトラッキング
- 未完了の場合の理由記録
8. 権限とロール
- PO/SM/開発者のロール管理
- 編集権限・閲覧権限の制御
9. 統合・拡張性
- GitHub/GitLabなどのリポジトリ連携
- CI/CDのステータス連携
- カレンダー・チャットツール連携
10. 使いやすさ
- モバイル対応
- 検索・フィルタ・タグ
- テンプレート(スプリント計画、レトロの振り返り項目)
---
必要ならこの内容をさらに「最小構成(MVP)」と「拡張機能」に分けて整理できます。必要な粒度や対象ユーザー(個人/チーム/企業)も教えてもらえると精度を上げられます。
GPT-5.2 の出力
目的・背景から書き起こして、透明性・検査・適応の思想を明示した構成です。ドキュメントとしての完成度が高く、読み手を想定した構造になっています。
特徴
- スクラムの目的(「なぜ」)から説明
- 役割・成果物・イベントに「実務での意味」を併記
- MVPと拡張機能を明確に分離
- 指標の使い方に注意書き(「個人評価や数値目標化には向きません」)
所感
目的・背景がちゃんと書かれているため、後から見返したときに「なぜこの機能が必要か」が理解できます。文章の流れも自然で、ドキュメントとして完成度が高い点が特徴です。
目的
スクラムは、複雑な問題に対して「短いサイクルで価値を検証しながら改善する」ためのフレームワークです。固定の手順書ではなく、透明性・検査・適応を繰り返して成果とプロセスを継続的に高めます。
役割(Accountabilities)
- プロダクトオーナー(PO): 価値最大化に責任。プロダクトバックログを整備し、優先順位を決め、受け入れ可否を判断する。
- スクラムマスター(SM): スクラムが機能することに責任。障害除去、ファシリテーション、コーチング、スクラムの理解促進。
- 開発者(Developers): インクリメント(完成の定義を満たす成果物)を作ることに責任。見積もり、実装、品質担保、日々の計画調整。
成果物(Artifacts)
- プロダクトバックログ: 価値の高い順に並んだ「やることの一覧」。アイテムは独立して追加・分割・並べ替えされる。
- スプリントバックログ: スプリントで達成する目的(スプリントゴール)と、それを実現する選択済みのバックログアイテム、作業計画。
- インクリメント: スプリントの成果。完成の定義(DoD)を満たし、リリース可能な品質であることが前提。
イベント(Events)
- スプリント(通常1〜4週間): 価値提供の最小サイクル。途中で品質を落とす「未完成を積む」より、DoDを満たす完成を優先。
- スプリントプランニング: 何を(Why/What)・どうやって(How)作るかを合意し、スプリントゴールを定める。
- デイリースクラム(15分): 開発者が計画を点検し、必要に応じて当日の作業を調整する。報告会ではなく、次の24時間の協働のため。
- スプリントレビュー: ステークホルダーと成果を見て、プロダクトバックログを更新する(学びを反映)。
- レトロスペクティブ: チームのやり方を点検し、次スプリントで試す改善アクションを決める。
代表的な運用の流れ(例)
1. プロダクトバックログ整備(継続): 要求を分割し、受け入れ条件を明確化し、優先順位を更新する。
2. スプリントプランニング: スプリントゴールを決め、取り込むアイテムを選び、作業の進め方を合意する。
3. 実装(スプリント中): タスクを進め、デイリースクラムで計画を調整。DoDを満たすよう品質を維持。
4. レビュー: 成果をデモし、フィードバックから次の優先順位や方針を更新。
5. レトロ: うまくいったこと・課題・次に試す改善を決め、実行可能な小さなアクションに落とす。
よく使われる補助概念(必須ではないが一般的)
- ユーザーストーリー、受け入れ条件(AC)、ストーリーポイント(相対見積もり)
- カンバンボード(ToDo/Doing/Done)、WIP制限
- バーンダウン/バーンアップ、ベロシティ(指標は目的を持って使い、目標化しない)
---
スクラム寄りタスク管理アプリに必要な機能整理
前提(このアプリが支援すること)
- 透明性: 「何が」「なぜ」「今どこまで」進んでいるかを誰でも把握できる
- 検査: スプリント/成果/プロセスを振り返るための情報が揃う
- 適応: 学びに応じてバックログや進め方を素早く更新できる
データモデル(最小)
- ワークスペース/組織
- プロダクト(またはプロジェクト)
- メンバー(役割: PO/SM/Developer/Viewer など)
- プロダクトバックログアイテム(PBI)
- タイトル、説明、価値/優先度、受け入れ条件、見積もり(任意)、ラベル、添付、関連リンク
- スプリント
- 期間、スプリントゴール、稼働日/容量(任意)
- タスク
- PBI配下の作業。担当者、状態、見積もり(時間など任意)、チェックリスト
- コメント/履歴(意思決定と変更のトレーサビリティ)
---
MVP(まず入れるべきコア機能)
1) バックログ管理
- PBIの作成・編集・削除(論理削除含む)
- 優先順位の並べ替え(ドラッグ&ドロップ等)
- 詳細(説明、受け入れ条件、添付/リンク、ラベル)
- 分割/複製(大きすぎるアイテムを分ける支援)
- 検索・フィルタ(担当、ラベル、状態、期間)
2) スプリント運用
- スプリント作成(開始日/終了日、ゴール)
- バックログからスプリントへ取り込み(計画の確定)
- スプリントバックログ(PBI+タスク一覧)
- スプリント内の状態遷移(例: ToDo/Doing/Review/Done)
- スプリント完了(成果の確定、未完了アイテムの戻し/繰越)
3) ボード(可視化)
- スプリントボード(カラム編集、並べ替え)
- スイムレーン(PBI単位/担当者単位など、最初はどちらかで十分)
- WIPの見える化(簡易でも良い)
4) チームのコミュニケーション
- コメント(PBI/タスク/スプリント)
- メンション、通知(最小はアプリ内通知)
- 変更履歴(誰がいつ何を変えたか)
5) 権限と基本設定
- ワークスペース/プロダクトのメンバー管理
- 権限(閲覧/編集/管理)
- カラム名、ラベル、テンプレ(最小)
---
スクラム色を強める「あると効く」機能(優先度高)
スプリントプランニング支援
- 容量/キャパシティ(メンバーの稼働日、休日、予定)と取り込み量の比較
- 見積もり(ストーリーポイント)入力と合計表示
- ゴールに対する関連度(ゴールに紐づくタグ/チェック)
DoD(完成の定義)と品質ゲート
- DoDチェックリスト(プロダクト共通/スプリント共通/アイテム個別)
- Doneに移す前の必須条件(例: テスト/レビュー完了など)
レビュー/レトロの記録
- レビュー議事メモ、フィードバック項目、次のバックログ化
- レトロボード(Keep/Problem/Try など)と改善アクションのタスク化
---
レポート・指標(使い方に注意しつつ有用)
- バーンダウン/バーンアップ
- ベロシティ推移(スプリントごと)
- リードタイム/サイクルタイム(カンバン寄り)
- フロー効率(任意)
※指標は「改善のための会話の材料」であり、個人評価や数値目標化には向きません。
---
便利機能(運用規模が上がるほど効く)
- テンプレート(ストーリー、バグ、改善、DoD)
- 依存関係(Blocked by / Blocks)とブロッカー表示
- リリース/バージョン、ロードマップ(簡易タイムライン)
- 外部連携(GitHub/GitLab、Slack/Teams、カレンダー)
- インポート/エクスポート(CSV/JSON)、API、Webhook
- 多言語、アクセシビリティ、モバイル対応
- 監査ログ、SSO、データ保持ポリシー(企業向け)
---
画面(最小構成の案)
- バックログ(優先順位リスト+詳細パネル)
- スプリント(ゴール、取り込み、スプリントバックログ)
- ボード(状態遷移、担当/ラベルフィルタ)
- レポート(バーンダウン等は後からでも可)
- レトロ(テンプレ+Tryをタスク化)
- 設定(メンバー/権限、カラム、ラベル、DoD)
---
最初の実装スコープ提案(例)
1. バックログ + スプリント作成 + スプリントへの取り込み
2. スプリントボード(状態遷移)+ コメント + 通知(アプリ内)
3. スプリント完了フロー(未完了の戻し/繰越)+ 履歴
4. DoDチェック + レトロ(Tryをタスク化)
5. レポート/連携/高度な権限(必要に応じて)
Codex 5.3 の出力
GPT-5.2とCodex 5.2の中間を取ったような構成になっています。目的は記載されていますが、出力形式は依然として箇条書き中心でエンジニア寄りです。
特徴
- 目的・ロール・イベントの説明はあり(GPT-5.2寄り)
- 箇条書き・見出し構造はエンジニア的(Codex 5.2寄り)
- 実務フロー・補足が充実
所感
5.2(GPT)に近づこうとしている方向性は感じられます。目的や背景をまとめるようになった点は進化ですが、文章の読みやすさやトーンは依然として「仕様書」寄りです。ドキュメント作成には、GPT-5.2の方が向いています。
1. 一般的なスクラムのやり方(概要)
1.1 スクラムの目的
- 価値の高いプロダクトを短いサイクルで継続的に届ける
- 変化する要求に対して、計画を固定せずに適応する
1.2 主要ロール
プロダクトオーナー (PO)- プロダクトバックログの優先順位を決める
- 何を作るか(価値)に責任を持つ
スクラムマスター (SM)- スクラムが正しく回るよう支援する
- プロセス上の障害を取り除く
開発チーム- スプリント内で成果物を作る
- どう作るか(実装)に責任を持つ
1.3 主要イベント
スプリント(通常1〜4週間)- 一定期間で実際に動く成果を作る時間枠
スプリントプランニング- スプリントで何をやるかを決める
- バックログ項目を選び、実行可能な計画を立てる
デイリースクラム- 毎日短時間で進捗・課題・次の動きを確認
スプリントレビュー- 完成した成果物を確認し、フィードバックを得る
スプリントレトロスペクティブ- 進め方を振り返り、次スプリントの改善を決める
1.4 主要成果物(アーティファクト)
プロダクトバックログ- 実現したい項目の優先順位付き一覧
スプリントバックログ- 今スプリントで実施する項目と実行計画
インクリメント- 完了の定義を満たした成果物の増分
Definition of Done (DoD)- 「完了」と見なす共通基準
1.5 実務でよくある流れ
1. POがバックログを更新し優先順位を整理
2. プランニングでスプリント目標と実施項目を決定
3. 開発中はデイリーで状況共有し、必要に応じて調整
4. レビューで成果確認と次の要求を収集
5. レトロで改善アクションを決め、次スプリントに反映
---
2. スクラム運用を支えるタスク管理機能(要件整理)
2.1 バックログ管理
- プロダクトバックログ項目(PBI)を作成・編集・削除
- 優先順位付け(ドラッグ&ドロップ、スコア順など)
- エピック/ストーリー/タスクの階層管理
- 受け入れ条件(Acceptance Criteria)記載
- 見積(ストーリーポイント、工数)設定
- バックログの状態管理(未着手/準備中/完了など)
2.2 スプリント計画・運用
- スプリントの作成(期間、目標、参加メンバー)
- バックログからスプリントへの取り込み
- チーム容量(Capacity)を見ながら計画
- スプリントボード(ToDo/In Progress/Done)
- タスクの担当者、期限、依存関係の管理
- スプリント途中の追加・変更の履歴追跡
2.3 日次運用サポート
- デイリースクラム用の簡易入力
- 昨日やったこと
- 今日やること
- ブロッカー
- ブロッカーの可視化と通知
- メンバーごとの進捗サマリー表示
2.4 完了定義と品質管理
- DoDテンプレートの定義とプロジェクト適用
- タスク完了時にDoDチェックリストを必須化
- レビュー/QA/承認フローの状態管理
2.5 レビュー・振り返り
- スプリントレビュー記録(デモ対象、フィードバック)
- レトロ記録(Keep/Problem/Try)
- レトロで決まった改善アクションを次スプリントへ自動起票
2.6 可視化・レポート
- バーンダウンチャート
- ベロシティ推移
- 累積フロー図(Cumulative Flow Diagram)
- スプリント完了率、未完了持ち越し率
- ブロッカー滞留時間
2.7 通知・連携
- 締切超過、ステータス変更、メンション通知
- チャット連携(Slack/Teams)
- Git連携(PR、コミットとタスク紐付け)
- カレンダー連携(イベント通知)
2.8 権限・監査
- ロール別権限(PO/SM/メンバー/閲覧者)
- 更新履歴(誰がいつ何を変更したか)
- 監査ログ出力
2.9 使いやすさ・運用性
- モバイル対応
- 高速な検索・フィルタ・保存ビュー
- テンプレート(定例タスク、スプリント設定)
- インポート/エクスポート(CSV、JSON)
---
3. MVPで先に作るべき機能(優先度高)
3.1 必須(まず実装)
1. バックログ登録・優先順位管理
2. スプリント作成とバックログ取り込み
3. カンバン形式のスプリントボード
4. タスク詳細(担当者、期限、見積、説明)
5. コメント・更新履歴
6. ベーシックなバーンダウン表示
3.2 次点(早めに追加)
1. デイリー入力とブロッカー管理
2. DoDチェックリスト
3. レトロ記録と改善アクション起票
4. 通知連携(まずはメールかSlackどちらか)
---
4. 画面イメージ(最小構成)
バックログ画面- 項目一覧、優先順位、見積、絞り込み
スプリント計画画面- 左: バックログ、右: スプリント候補
スプリントボード画面- カラム別タスク、担当者、ブロッカー表示
レポート画面- バーンダウン、ベロシティ
振り返り画面- Keep/Problem/Try とアクション管理
---
5. 補足
- スクラムは「イベントをこなすこと」ではなく「価値提供と改善サイクル」が主目的
- アプリ側は、入力負荷を下げつつ「透明性」と「検査・適応」を支える設計が重要
実装:UI/UXで見る各モデルの設計思想
Codex 5.2 の成果物
必要な機能を実装して動作させるという点では合格水準です。ただし、デザインやユーザー体験への配慮はやや限定的な印象です。
特徴
- 機能性:必要最小限の実装は完了
- 見た目:目立つ色味(オレンジ/ブラウン系)が特徴的
- UI構成:シンプルで、端的な作り
所感
動作するものは実装できていますが、デザイン面では独特の色調を選びやすい傾向があります。UI/UXの洗練度ではGPT-5.2に一歩譲る印象です。
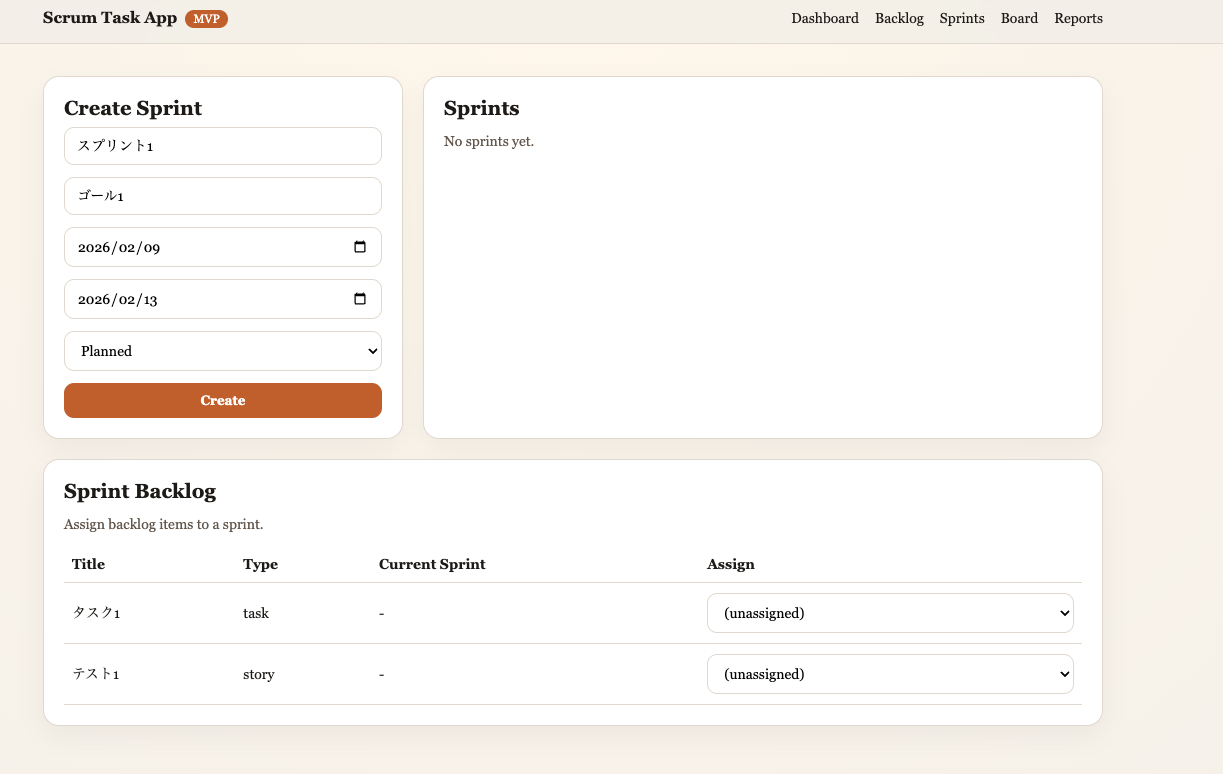
スプリント作成画面。オレンジ/ブラウン系の配色が特徴的
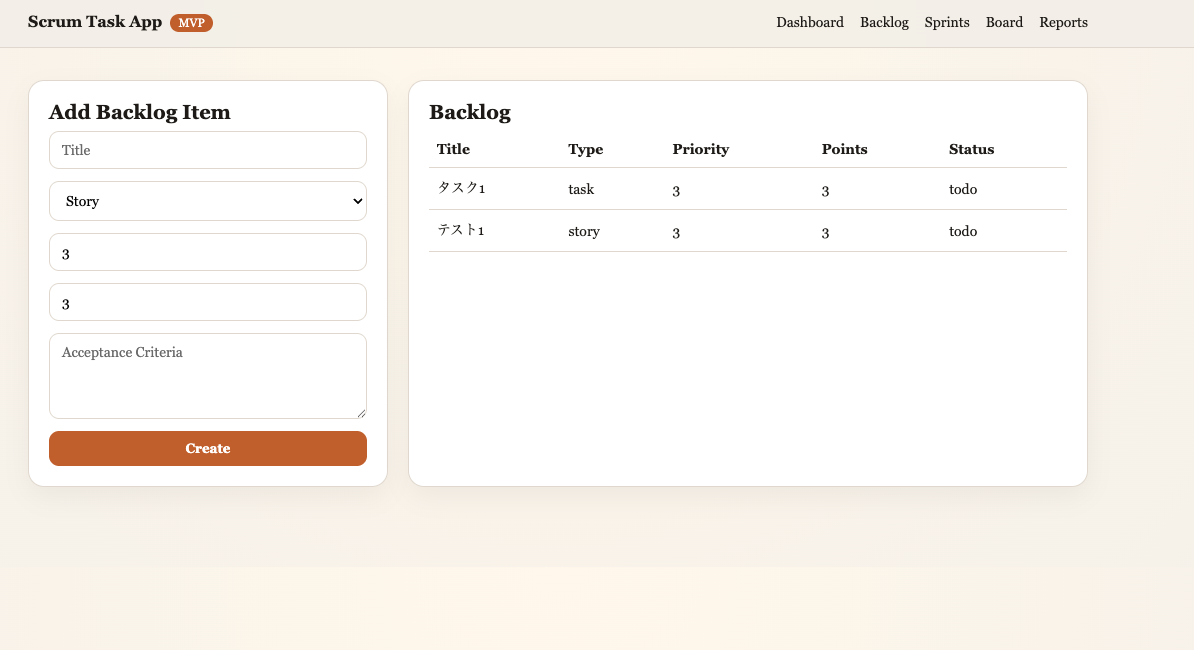
バックログ管理画面。機能は揃っているが、デザインは機能最小限
Codex 5.3 の成果物
情報を詰め込もうとする意欲は伝わりますが、一画面に多くの要素が集約され、レイアウトが崩れる箇所が見られました。
特徴
- 一画面に多機能を詰め込む傾向
- レイアウト崩れやCSS調整不足が散見
- 情報密度は高いが、操作性とのトレードオフが見える
所感
機能充実への意欲は感じられますが、情報設計まで対応しきれていません。UIの整理が追いついていない状態です。
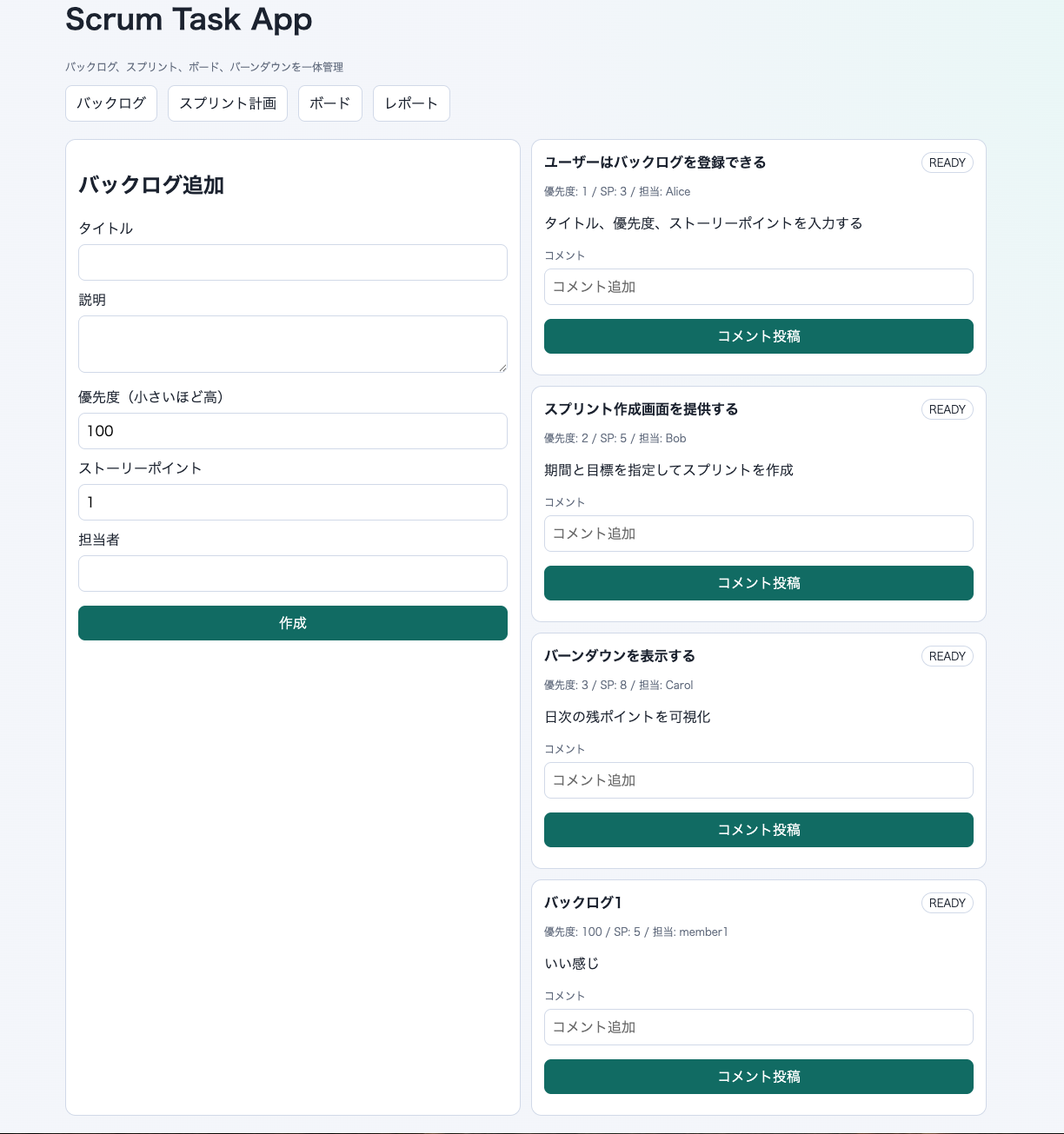
バックログ画面。
GPT-5.2 の成果物
デザインセンスと使いやすさが際立ちます。モーダル・ボタン配置・コンポーネント分割など、UI設計の判断が一貫して適切です。
特徴
- プラスボタンでモーダル表示→追加フォームを分離
- 視覚的な情報整理が優れている(カード、余白、階層)
- デザイン:現代的で洗練された印象
所感
UI設計のセンスが明らかに高く、操作性を意識したコンポーネント分割ができています。デザイン面ではGPT-5.2が頭一つ抜けている点が顕著です。
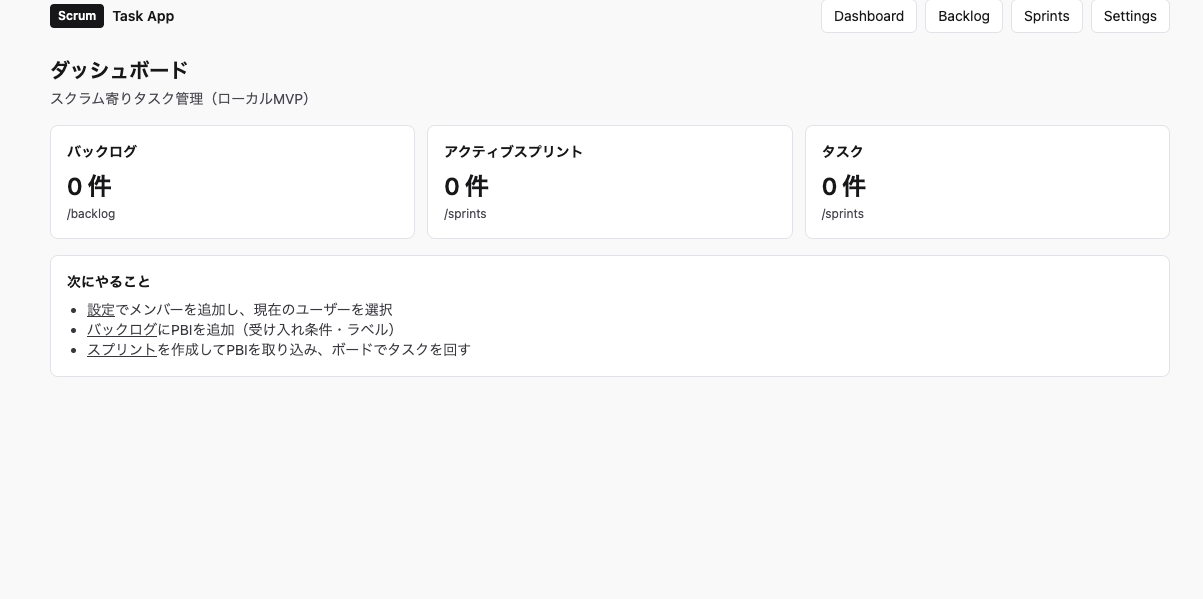
ダッシュボード画面。カード型UIで情報が整理されている
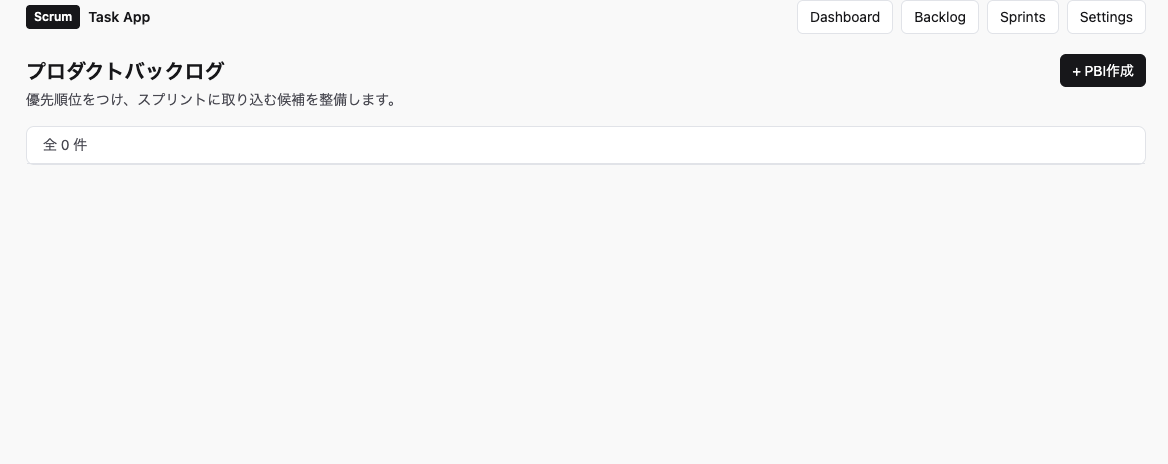
バックログ画面。プラスボタンでモーダルを開いて、追加フォームを表示する設計
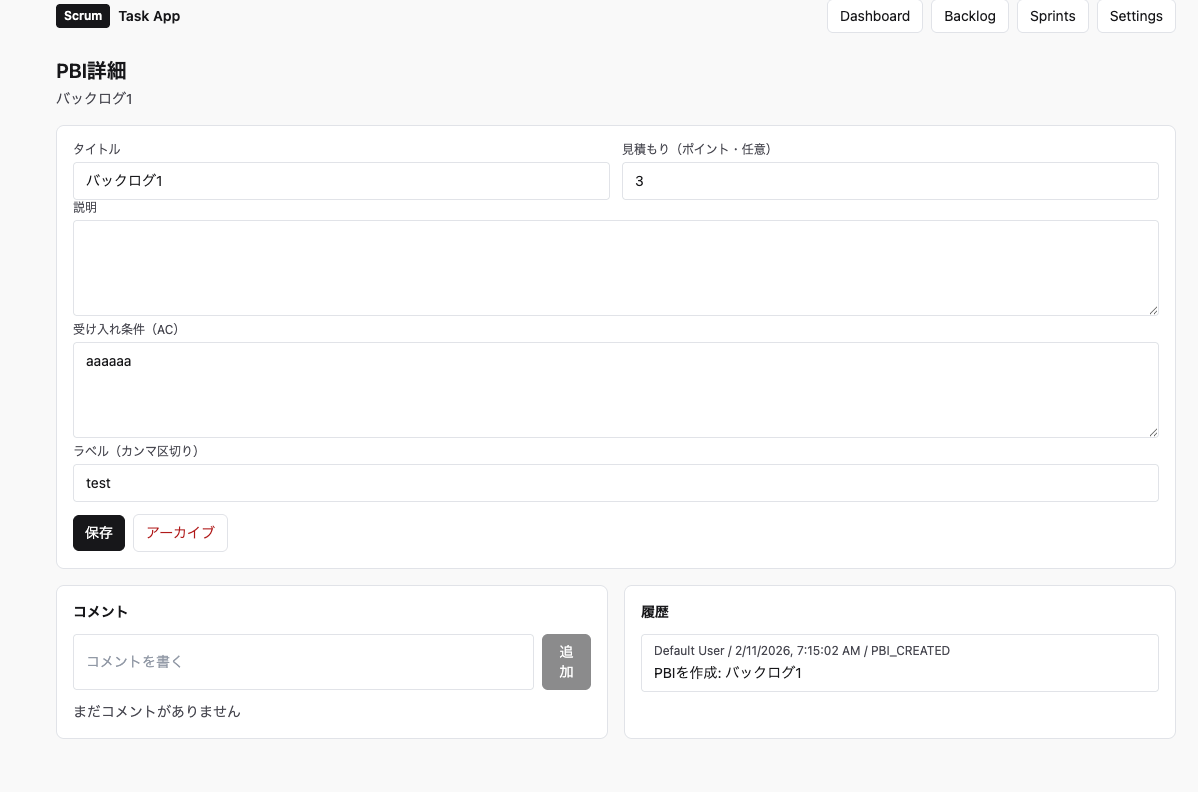
PBI詳細画面。視覚的な階層構造とコメント履歴が見やすい
追加検証:要件を統一して再実行
「Codex 5.3/5.2がGPT-5.2の要件で実装したらどうなるか?」を確認するため、GPT-5.2の要件mdを使って再実行してみました。
結果
- Codex 5.2:相変わらずオレンジ/ブラウン系の色味。UIは基本的に変わらず
- Codex 5.3:緑系の配色に変わりましたが、操作性の改善は見られず
結論
要件の質を揃えても、UI設計の判断はモデル固有の特性に大きく依存することが分かりました。GPT-5.2は「UI設計を内部で組み立てる段階」で優れた判断をしており、最終的な成果物の質が高くなっているように見えます。
> 注記:ここでの「UI/UXの評価」は、筆者が判断したものです。あくまで参考程度で捉えていただければと思います。
検証のまとめ
| 観点 | Codex 5.2 | Codex 5.3 | GPT-5.2 |
| 要件定義 | 箇条書き中心、背景なし | 中間(背景あり、箇条書き) | 背景・目的・構造が明確 |
| ドキュメント品質 | ✗ エンジニア向け仕様書 | △ 改善はあるが硬い | ○ 読み物として完成度高 |
| 実装(機能) | ○ 最小限は動作 | ○ 動作、情報密度高 | ○ 動作、洗練 |
| UI/UX設計 | △ 機械的、独特の色味 | △ 詰め込みすぎ、崩れあり | ◎ 設計センス・操作性が優秀 |
| 自然言語指示の理解 | △ 機能要件への変換は正確 | △ 改善はあるが直線的 | ○ 意図・背景を補完して整理 |
Webアプリ開発においてはGPT-5.2が適切な選択肢
本検証の範囲では、以下の特徴が観察されました。
- 要件定義フェーズ:GPT-5.2が背景・目的を補完し、読みやすいドキュメントを作成
- 実装フェーズ(UI/UX重視):GPT-5.2がデザインセンス・コンポーネント設計で優位
- 実装フェーズ(ロジック/改修重視):Codex 5.3が既存コード解析・差分実装で有利になる可能性がある
「文章で仕様を固めて、UIを含めて実装する」Webアプリケーション開発においては、現時点ではGPT-5.2が安定した成果を出しやすいと考えられます。
用途による選択指針
| 開発内容 | 推奨モデル | 理由 |
| Webアプリ開発(要件→UI/UX→実装) | GPT-5.2 | 要件整理・UI設計の面で優位 |
| 既存コード改修(複雑ロジック・多ファイル) | Codex 5.3の検討価値 | コード解析・差分実装に特化 |
| ロジック主体開発(データ処理・API等) | 実装試行で判断 | 内容次第で適性が変わる |
最適なモデル選択はプロジェクトの性質に左右されます。プロジェクト要件に基づいて、複数モデルの試用を検討することをお勧めします。